
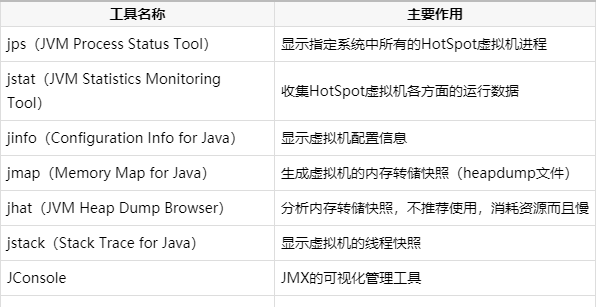
jvm 工具
堆:包括年轻代与老年代+字符串常量池,年轻代由一个Eden与两个Survivor区。
方法区:持久代与元空间都是方法区的实现,JDK1.8改为元空间。
stream 工具
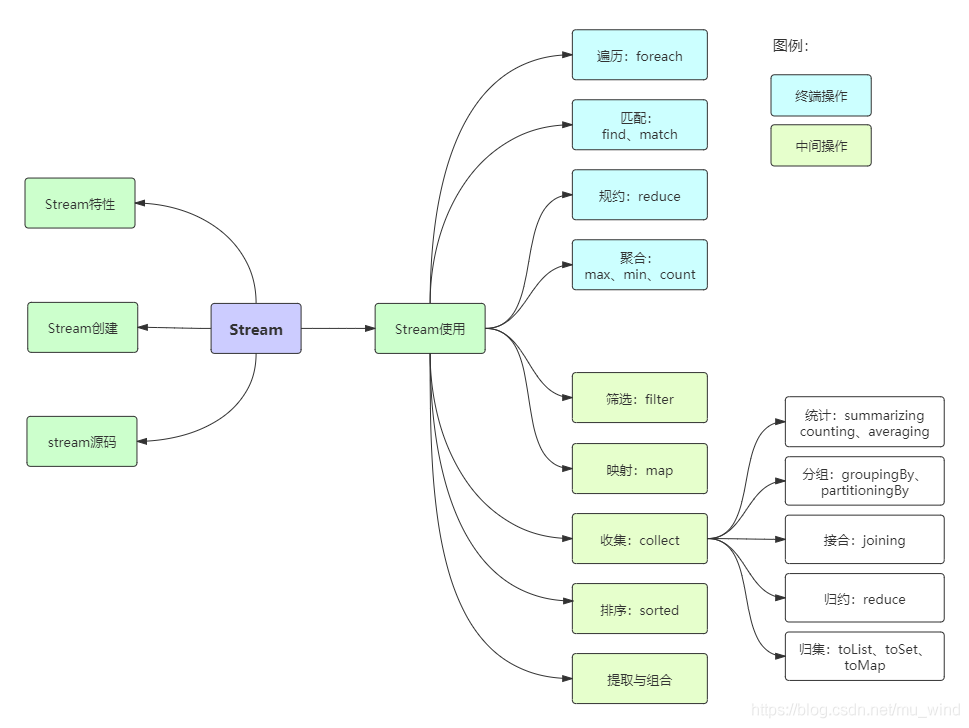
Stream.of(): 创建一个由指定元素组成的流
Stream<String> stream = Stream.of("apple", "banana", "orange");
Stream.iterate(): 生成一个无限流,通过迭代生成元素
Stream<Integer> stream = Stream.iterate(1, n -> n * 2);
Stream<Double> stream = Stream.generate(Math::random);
Stream.generate(): 生成一个无限流,通过提供的 Supplier 生成元素。
Stream.Builder 是一个用于逐步构建流的辅助工具。通过 add() 方法逐个添加元素,最后调用 build() 方法生成流.
❗❗❗Stream.generate和Stream.iterate()都要配合.limit()来使用,确保生成的元素的数量
IntSummaryStatistics statistics = IntStream.generate(() -> {
ThreadLocalRandom tlr = ThreadLocalRandom.current();
return tlr.nextInt();
})
.limit(100)
.summaryStatistics();
System.out.println(statistics);
Collectors.partitioningBy() ,根据返回值是否为 true,把集合分为两个列表,一个 true 列表,一个 false 列表
Map<Integer, List<String>> result = studentList.stream()
.collect(Collectors.groupingBy(Student::getAge,
Collectors.mapping(Student::getName, Collectors.toList())));
List<Integer> list = Arrays.asList(1, 2, 3, 4);
Double result = list.stream().collect(Collectors.collectingAndThen(Collectors.averagingLong(v -> {
System.out.println("v--" + v + "--> " + v );
return v ;
}),
s -> {
System.out.println(s);
System.out.println("s--" + s + "--> " + s * s);
return s * s;
}));
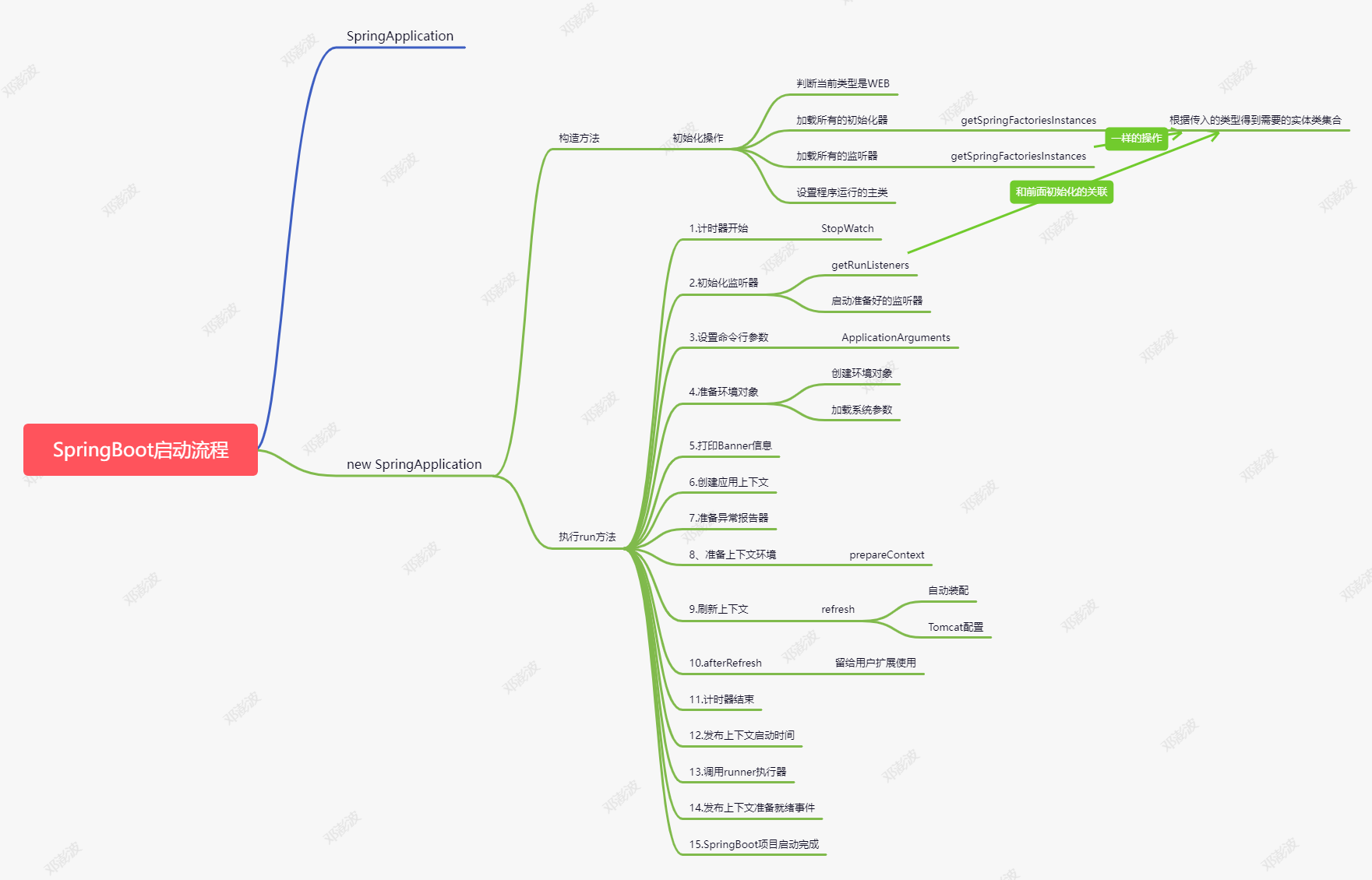
System.out.println(result);springboot 启动流程
策略模式也可以使用 map 解决
java
@Service("org")
public interface IxxxxxService<T> {
}
Map<string,IxxxxxService>java
mvn clean package -T 1C -DskipTests '-Dmaven.compile.fork=true'&&java -jar xxxx.jar --spring.profiles.active=dev --server.port=8085happens-before
程序次序规则(Program Order Rule):在一个线程内,按照控制流顺序,书写在前面的操作先行发生于书写在后面的操作。
管程锁定规则(Monitor Lock Rule):一个unlock操作先行发生于后面对同一个锁的lock操作。
volatile变量规则(Volatile Variable Rule):对一个volatile变量的写操作先行发生于后面对这个变量的读操作。
线程启动规则(Thread Start Rule):Thread对象start()方法先行发生于此线程的每一个动作。
线程终止规则(Thread Termination Rule):线程中的所有操作都先行发生于对此线程的终止检测,我们可以通过Thread.join()方法和Thread.isAlive()的返回值等手段检测线程是否已经终止执行。
线程中断规则(Thread Interruption Rule):对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过Thread.interrupted()方法检测到是否有中断发生。
对象终结规则(Finalizer Rule) :一个对象的初始化完成(构造函数结束)先行发生于它的finalize()方法的开始。
传递性(Transitivity):如果操作A先行发生于操作B,操作B先行发生于操作C,那就可以得出操作A先行发生于操作C的结论。
as-if-serial 语义的意思指:不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变。编译器,runtime 和处理器都必须遵守 as-if-serial 语义应用上文生命周期(14 个阶段)
1、创建spring应用上下文
2、上下文启动准备阶段
3、BeanFactory创建阶段
4、BeanFactory准备阶段
5、BeanFactory后置处理阶段
6、BeanFactory注册BeanPostProcessor阶段
7、初始化内建Bean:MessageSource
8、初始化内建Bean:Spring事件广播器
9、Spring应用上下文刷新阶段
10、Spring事件监听器注册阶段
11、单例bean实例化阶段
12、BeanFactory初始化完成阶段
13、Spring应用上下文启动完成阶段
14、Spring应用上下文关闭阶段@value("${}") @value("#{}")
@value("${}") 读取properties信息
@value("#{}") 读取bean信息springboot api 版本控制
1.请求头上添加 x-api-version 2.url上添加version
添加注解 ApiVersion
实现 RequestCondition
重写RequestMappingHandlerMapping
重新注入到WebMvcRegistrationsjava
【-D】要放到 -jar 前面,否则参数无效
java -jar xxxx --spring.profiles.active=dev --server.port=8085 --springfox.documentation.auto-startup=false --spring.jmx.enabled=false --spring.jpa.properties.hibernate.temp.use_jdbc_metadata_defaults=false --spring.devtools.add-properties=false --mybatis.configuration.log-impl=org.apache.ibatis.logging.nologging.NoLoggingImpl --logging.level.com.app286=info --server.compression.enabled=true --server.compression.mime-types=application/javascript,text/css,application/json,application/xml,text/html,text/xml,text/plain --server.compression.min-response-size=128
java -jar "-XX:+UseConcMarkSweepGC -Dspring.redis.host=127.0.0.1 -Dspring.redis.port=6379 -Dspring.redis.password=root -Dspring.redis.database=0 -Dspring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxx?userUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=Asia/Shanghai&&allowPublicKeyRetrieval=true -Dspring.datasource.username=root -Dspring.datasource.password=123456" xxx.warflyway
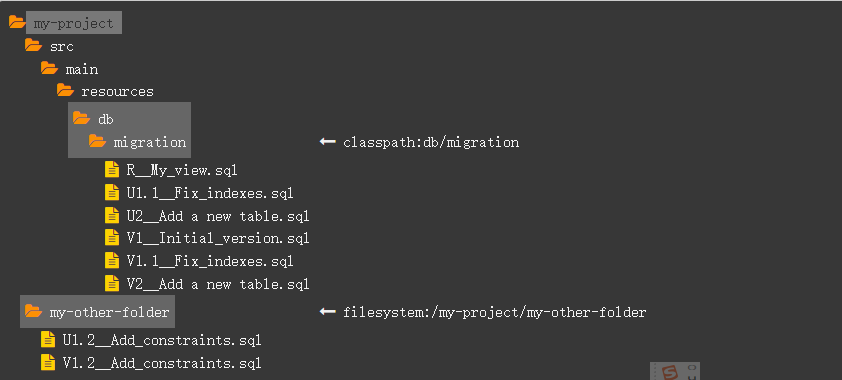
开源的数据库版本控制工具
API 接口设计
签名 为了防止 API 接口中的数据被篡改,很多时候我们需要对 API 接口做签名。 接口请求方将请求参数 + 时间戳 + 密钥拼接成一个字符串,然后通过 md5 等 hash 算法,生成一个前面 sign。 然后在请求参数或者请求头中,增加 sign 参数,传递给 API 接口。 API 接口的网关服务,获取到该 sign 值,然后用相同的请求参数 + 时间戳 + 密钥拼接成一个字符串,用相同的 m5 算法生成另外一个 sign,对比两个 sign 值是否相等。 如果两个 sign 相等,则认为是有效请求,API 接口的网关服务会将给请求转发给相应的业务系统。 如果两个 sign 不相等,则 API 接口的网关服务会直接返回签名错误。 问题来了:签名中为什么要加时间戳? 答:为了安全性考虑,防止同一次请求被反复利用,增加了密钥没破解的可能性,我们必须要对每次请求都设置一个合理的过期时间,比如:15分钟。 这样一次请求,在 15 分钟之内是有效的,超过 15 分钟,API 接口的网关服务会返回超过有效期的异常提示。 目前生成签名中的密钥有两种形式: 一种是双方约定一个固定值 privateKey。 另一种是 API 接口提供方给出 AK/SK 两个值,双方约定用 SK 作为签名中的密钥。AK 接口调用方作为 header 中的 accessKey 传递给 API 接口提供方,这样 API 接口提供方可以根据 AK 获取到 SK,而生成新的 sgin。
ip 白名单 为了进一步加强 API 接口的安全性,防止接口的签名或者加密被破解了,攻击者可以在自己的服务器上请求该接口。 需求限制请求 ip,增加 ip 白名单。 只有在白名单中的 ip 地址,才能成功请求 API 接口,否则直接返回无访问权限。 ip 白名单也可以加在 API 网关服务上。 但也要防止公司的内部应用服务器被攻破,这种情况也可以从内部服务器上发起 API 接口的请求。 这时候就需要增加 web 防火墙了,比如:ModSecurity 等。
请求日志 在第三方平台请求你的 API 接口时,接口的请求日志非常重要,通过它可以快速的分析和定位问题。 我们需要把 API 接口的请求 url、请求参数、请求头、请求方式、响应数据和响应时间等,记录到日志文件中。 最好有 traceId,可以通过它串联整个请求的日志,过滤多余的日志。 当然有些时候,请求日志不光是你们公司开发人员需要查看,第三方平台的用户也需要能查看接口的请求日志。 这时就需要把日志落地到数据库,比如:mongodb 或者 elastic search,然后做一个 UI 页面,给第三方平台的用户开通查看权限。这样他们就能在外网查看请求日志了,他们自己也能定位一部分问题。
幂等设计 第三方平台极有可能在极短的时间内,请求我们接口多次,比如:在 1 秒内请求两次。有可能是他们业务系统有 bug,或者在做接口调用失败重试,因此我们的 API 接口需要做幂等设计。 也就是说要支持在极短的时间内,第三方平台用相同的参数请求 API 接口多次,第一次请求数据库会新增数据,但第二次请求以后就不会新增数据,但也会返回成功。 这样做的目的是不会产生错误数据。 我们在日常工作中,可以通过在数据库中增加唯一索引,或者在 redis 保存 requestId 和请求参来保证接口幂等性。 对接口幂等性感兴趣的小伙伴,可以看看我的另一篇文章《高并发下如何保证接口的幂等性?》,里面有非常详细的介绍。
限制记录条数 对于对我提供的批量接口,一定要限制请求的记录条数。 如果请求的数据太多,很容易造成 API 接口超时等问题,让 API 接口变得不稳定。 通常情况下,建议一次请求中的参数,最多支持传入 500 条记录。 如果用户传入多余 500 条记录,则接口直接给出提示。 建议这个参数做成可配置的,并且要事先跟第三方平台协商好,避免上线后产生不必要的问题。
压测 上线前我们务必要对 API 接口做一下压力测试,知道各个接口的 qps 情况。 以便于我们能够更好的预估,需要部署多少服务器节点,对于 API 接口的稳定性至关重要。 之前虽说对 API 接口做了限流,但是实际上 API 接口是否能够达到限制的阀值,这是一个问号,如果不做压力测试,是有很大风险的。 比如:你 API 接口限流 1 秒只允许 50 次请求,但实际 API 接口只能处理 30 次请求,这样你的 API 接口也会处理不过来。 我们在工作中可以用 jmeter 或者 apache benc 对 API 接口做压力测试。
数据脱敏 有时候第三方平台调用我们 API 接口时,获取的数据中有一部分是敏感数据,比如:用户手机号、银行卡号等等。 这样信息如果通过 API 接口直接保留到外网,是非常不安全的,很容易造成用户隐私数据泄露的问题。 这就需要对部分数据做数据脱敏了。 我们可以在返回的数据中,部分内容用星号代替。 已用户手机号为例:182****887。 这样即使数据被泄露了,也只泄露了一部分,不法分子拿到这份数据也没啥用。
接口实现考虑熔断和降级 当前互联网系统一般都是分布式部署的。而分布式系统中经常会出现某个基础服务不可用,最终导致整个系统不可用的情况, 这种现象被称为服务雪崩效应。
接口的版本控制
完整的接口文档 说实话,一份完整的 API 接口文档,在双方做接口对接时,可以减少很多沟通成本,让对方少走很多弯路。 接口文档中需要包含如下信息: 接口地址 请求方式,比如:post 或 get 请求参数和字段介绍 返回值和字段介绍 返回码和错误信息 加密或签名示例 完整的请求 demo 额外的说明,比如:开通 ip 白名单。
设计接口时,充分考虑接口的可扩展性 要根据实际业务场景设计接口,充分考虑接口的可扩展性。 比如你接到一个需求:是用户添加或者修改员工时,需要刷脸。那你是反手提供一个员工管理的提交刷脸信息接口?还是先思考:提交刷脸是不是通用流程呢?比如转账或者一键贴现需要接入刷脸的话,你是否需要重新实现一个接口呢?还是当前按业务类型划分模块,复用这个接口就好,保留接口的可扩展性。 如果按模块划分的话,未来如果其他场景比如一键贴现接入刷脸的话,不用再搞一套新的接口,只需要新增枚举,然后复用刷脸通过流程接口,实现一键贴现刷脸的差异化即可。
优化接口耗时,远程串行考虑改并行调用
代码锁的粒度控制好 我们写代码时,如果不涉及到共享资源,就没有必要锁住的。这就好像你上卫生间,不用把整个家都锁住,锁住卫生间门就可以了。
异步处理 一般的 API 接口的逻辑都是同步处理的,请求完之后立刻返回结果。 但有时候,我们的 API 接口里面的业务逻辑非常复杂,特别是有些批量接口,如果同步处理业务,耗时会非常长。 这种情况下,为了提升 API 接口的性能,我们可以改成异步处理。 在 API 接口中可以发送一条 mq 消息,然后直接返回成功。之后,有个专门的 mq 消费者去异步消费该消息,做业务逻辑处理。 直接异步处理的接口,第三方平台有两种方式获取到。 第一种方式是:我们回调第三方平台的接口,告知他们 API 接口的处理结果,很多支付接口就是这么玩的。 第二种方式是:第三方平台通过轮询调用我们另外一个查询状态的 API 接口,每隔一段时间查询一次状态,传入的参数是之前的那个 API 接口中的 id 集合。
统一封装异常 我们的 API 接口需要对异常进行统一处理。 不知道你有没有遇到过这种场景:有时候在 API 接口中,需要访问数据库,但表不存在,或者 sql 语句异常,就会直接把 sql 信息在 API 接口中直接返回。 返回值中包含了异常堆栈信息、数据库信息、错误代码和行数等信息。 如果直接把这些内容暴露给第三方平台,是很危险的事情。 有些不法分子,利用接口返回值中的这些信息,有可能会进行 sql 注入或者直接脱库,而对我们系统造成一定的损失。 因此非常有必要对 API 接口中的异常做统一处理,把异常转换成这样: {"code":500,"message":"服务器内部错误","data":null } 返回码 code 是 500,返回信息 message 是服务器内部异常。 这样第三方平台就知道是 API 接口出现了内部问题,但不知道具体原因,他们可以找我们排查问题。 我们可以在内部的日志文件中,把堆栈信息、数据库信息、错误代码行数等信息,打印出来。 我们可以在 gateway 中对异常进行拦截,做统一封装,然后给第三方平台的是处理后没有敏感信息的错误信息。
加密 有些时候,我们的 API 接口直接传递的非常重要的数据,比如:用户的银行卡号、转账金额、用户身份证等,如果将这些参数,直接明文,暴露到公网上是非常危险的事情。 由此,我们需要对数据进行加密。 目前使用比较多的是用 BASE64 加解密。 我们可以将所有的数据,安装一定的规律拼接成一个大的字符串,然后在加一个密钥,拼接到一起。 然后使用 JDK1.8 之后的 Base64 工具类处理,效果如下: 【加密前的数据】www.baidu.com 【加密后的数据】d3d3LmJhaWR1LmNvbQ== 为了安全性,使用 Base64 可以加密多次。 API 接口的调用方在传递参数时,body 中只有一个参数 data,它就是 base64 之后的加密数据。 API 接口的网关服务,在接收到 data 数据后,根据双方事先预定的密钥、加密算法、加密次数等,进行解密,并且反序列化出参数数据。
限流 如果你的 API 接口被第三方平台调用了,这就意味着着,调用频率是没法控制的。 第三方平台调用你的 API 接口时,如果并发量一下子太高,可能会导致你的 API 服务不可用,接口直接挂掉。 由此,必须要对 API 接口做限流。 限流方法有三种: 对请求 ip 做限流:比如同一个 ip,在一分钟内,对 API 接口总的请求次数,不能超过 10000 次。 对请求接口做限流:比如同一个 ip,在一分钟内,对指定的 API 接口,请求次数不能超过 2000 次。 对请求用户做限流:比如同一个 AK/SK 用户,在一分钟内,对 API 接口总的请求次数,不能超过 10000 次。 我们在实际工作中,可以通过 nginx,redis 或者 gateway 实现限流的功能。
参数校验 我们需要对 API 接口做参数校验,比如:校验必填字段是否为空,校验字段类型,校验字段长度,校验枚举值等等。 这样做可以拦截一些无效的请求。 比如在新增数据时,字段长度超过了数据字段的最大长度,数据库会直接报错。 但这种异常的请求,我们完全可以在 API 接口的前期进行识别,没有必要走到数据库保存数据那一步,浪费系统资源。 有些金额字段,本来是正数,但如果用户传入了负数,万一接口没做校验,可能会导致一些没必要的损失。 还有些状态字段,如果不做校验,用户如果传入了系统中不存在的枚举值,就会导致保存的数据异常。 由此可见,做参数校验是非常有必要的。 在 Java 中校验数据使用最多的是 hiberate 的 Validator 框架,它里面包含了@Null、@NotEmpty、@Size、@Max、@Min 等注解。 用它们校验数据非常方便。 当然有些日期字段和枚举字段,可能需要通过自定义注解的方式实现参数校验。 6. 统一返回值 我之前调用过别人的 API 接口,正常返回数据是一种 json 格式,比如: {"code":0,"message":null,"data":[{"id":123,"name":"abc"}] }, 签名错误返回的 json 格式: {"code":1001,"message":"签名错误","data":null } 没有数据权限返回的 json 格式: {"rt":10,"errorMgt":"没有权限","result":null } 这种是比较坑的做法,返回值中有多种不同格式的返回数据,这样会导致对接方很难理解。 出现这种情况,可能是 API 网关定义了一直返回值结构,业务系统定义了另外一种返回值结构。如果是网关异常,则返回网关定义的返回值结构,如果是业务系统异常,则返回业务系统的返回值结构。 但这样会导致 API 接口出现不同的异常时,返回不同的返回值结构,非常不利于接口的维护。 其实这个问题我们可以在设计 API 网关时解决。 业务系统在出现异常时,抛出业务异常的 RuntimeException,其中有个 message 字段定义异常信息。 所有的 API 接口都必须经过 API 网关,API 网关捕获该业务异常,然后转换成统一的异常结构返回,这样能统一返回值结构。
停止端口
ps -ef | grep xxxx| grep -v grep|awk '{print $2}'| xargs kill -9
技术要点
系统开发
- 高内聚/低耦合 高内聚指一个软件模块是由相关性很强的代码组成,只负责一项任务,也就是常说的单一责任原则。模块的内聚反映模块内部联系的紧密程度。
模块之间联系越紧密,其耦合性就越强,模块的独立性则越差。模块间耦合高低取决于模块间接口的复杂性、调用的方式及传递的信息。一个完整的系统,模块与模块之间,尽可能的使其独立存在。通常程序结构中各模块的内聚程度越高,模块间的耦合程度就越低。
过度设计 过度设计就是进行了过多的面向未来的设计或者说把相对简单的事情想复杂了,过度追求模块化、可扩展性、设计模式等,为系统增加了不必要的复杂度。
过早优化 过早指的不是在开发过程的早期,而是在还没弄清楚需求未来的变化的走向的时候。你的优化不仅可能导致你无法很好地实现新的需求,而且你对优化的预期的猜测有可能还是错的,导致实际上你除了把代码变复杂以外什么都没得到。
正确的方法是,先有质量地实现你的需求,写够 testcase,然后做 profile 去找到性能的瓶颈,这个时候才做优化。
重构 (Refactoring) 重构(Refactoring)就是通过调整程序代码改善软件的质量、性能,使其程序的设计模式和架构更趋合理,提高软件的扩展性和维护性。
破窗效应 又称破窗理论,破窗效应(Broken windows theory)是犯罪学的一个理论。此理论认为环境中的不良现象如果被放任存在,会诱使人们仿效,甚至变本加厉。一幢有少许破窗的建筑为例,如果那些窗不被修理好,可能将会有破坏者破坏更多的窗户。最终他们甚至会闯入建筑内,如果发现无人居住,也许就在那里定居或者纵火。
应用在软件工程上就是,一定不能让系统代码或者架构设计的隐患有冒头的机会,否则随着时间的推移,隐患会越来越重。反之,一个本身优质的系统,会让人不由自主的写出优质的代码。
互不信任原则 指在程序运行上下游的整个链路中,每个点都是不能保证绝对可靠的,任何一个点都可能随时发生故障或者不可预知的行为,包括机器网络、服务本身、依赖环境、输入和请求等,因此要处处设防。
持久化 (Persistence) 持久化是将程序数据在临时状态和持久状态间转换的机制。通俗的讲,就是临时数据(比如内存中的数据,是不能永久保存的)持久化为持久数据(比如持久化至数据库或者本地磁盘中,能够长久保存)。
临界区 临界区用来表示一种公共资源或者说是共享数据,可以被多个线程使用,但是每一次,只能有一个线程使用它,一旦临界区资源被占用,其他线程要想使用这个资源,就必须等待。
阻塞/非阻塞 阻塞和非阻塞通常形容多线程间的相互影响。比如一个线程占用了临界区资源,那么其它所有需要这个资源的线程就必须在这个临界区中进行等待,等待会导致线程挂起。这种情况就是阻塞。此时,如果占用资源的线程一直不愿意释放资源,那么其它所有阻塞在这个临界区上的线程都不能工作。而非阻塞允许多个线程同时进入临界区。
同步/异步 通常同步和异步是指函数/方法调用方面。
同步就是在发出一个函数调用时,在没有得到结果之前,该调用就不返回。异步调用会瞬间返回,但是异步调用瞬间返回并不代表你的任务就完成了,他会在后台起个线程继续进行任务,等任务执行完毕后通过回调 callback 或其他方式通知调用方。
- 并发/并行 并行(parallel)指在同一时刻,有多条指令在多个处理器上同时执行。所以无论从微观还是从宏观来看,二者都是一起执行的。
并发(concurrency)指在同一时刻只能有一条指令执行,但多个进程指令被快速的轮换执行,使得在宏观上具有多个进程同时执行的效果,但在微观上并不是同时执行的,只是把时间分成若干段,使多个进程快速交替的执行。
架构设计
高并发 (High Concurrency) 由于分布式系统的问世,高并发(High Concurrency)通常是指通过设计保证系统能够同时并行处理很多请求。通俗来讲,高并发是指在同一个时间点,有很多用户同时的访问同一 API 接口或者 Url 地址。它经常会发生在有大活跃用户量,用户高聚集的业务场景中。
高可用 (High Availability) 高可用 HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,一个系统经过专门的设计,以减少停工时间,而保持其服务的高度可用性。
读写分离 为了确保数据库产品的稳定性,很多数据库拥有双机热备功能。也就是,第一台数据库服务器,是对外提供增删改业务的生产服务器;第二台数据库服务器,主要进行读的操作。
冷备/热备 冷备:两个服务器,一台运行,一台不运行做为备份。这样一旦运行的服务器宕机,就把备份的服务器运行起来。冷备的方案比较容易实现,但冷备的缺点是主机出现故障时备机不会自动接管,需要主动切换服务。
热备:即是通常所说的 active/standby 方式,服务器数据包括数据库数据同时往两台或多台服务器写。当 active 服务器出现故障的时候,通过软件诊测(一般是通过心跳诊断)将 standby 机器激活,保证应用在短时间内完全恢复正常使用。当一台服务器宕机后,自动切换到另一台备用机使用。
异地多活 异地多活一般是指在不同城市建立独立的数据中心,“活”是相对于冷备份而言的,冷备份是备份全量数据,平时不支撑业务需求,只有在主机房出现故障的时候才会切换到备用机房,而多活,是指这些机房在日常的业务中也需要走流量,做业务支撑。
负载均衡 (Load Balance) 负载均衡,是对多台服务器进行流量分发的负载均衡服务。可在多个实例间自动分配应用程序的对外服务能力,通过消除单点故障提升应用系统的可用性,让您实现更高水平的应用程序容错能力,从而无缝提供分配应用程序流量所需的负载均衡容量,为您提供高效、稳定、安全的服务。
动静分离 动静分离是指在 web 服务器架构中,将静态页面与动态页面或者静态内容接口和动态内容接口分开不同系统访问的架构设计方法,进而提升整个服务访问性能和可维护性。
集群 单台服务器的并发承载能力总是有限的,当单台服务器处理能力达到性能瓶颈的时,将多台服务器组合起来提供服务,这种组合方式称之为集群,集群中每台服务器就叫做这个集群的一个“节点”,每个节点都能提供相同的服务,从而成倍的提升整个系统的并发处理能力。
分布式 分布式系统就是将一个完整的系统按照业务功能拆分成很多独立的子系统,每个子系统就被称为“服务”,分布式系统将请求分拣和分发到不同的子系统,让不同的服务来处理不同的请求。在分布式系统中,子系统独立运行,它们之间通过网络通信连接起来实现数据互通和组合服务。
CAP 理论 CAP 理论,指的是在一个分布式系统中,Consistency(一致性)、Availability(可用性)、Partition Tolerance(分区容错性),不能同时成立。
一致性:它要求在同一时刻点,分布式系统中的所有数据备份都相同或者都处于同一状态。 可用性:在系统集群的一部分节点宕机后,系统依然能够正确的响应用户的请求。 分区容错性:系统能够容忍节点之间的网络通信的故障。 简单的来说,在一个分布式系统中,最多能支持上面的两种属性。但显然既然是分布式注定我们是必然要进行分区,既然分区,我们就无法百分百避免分区的错误。因此,我们只能在一致性和可用性去作出选择。
放弃P:放弃P就意味着放弃了扩展性。就是把所有数据放在一个节点上,就不是分布式了 放弃A:系统遇到故障时,在等待时间内系统无法对外提供正常服务,即不可用 放弃C:放弃强一致性,而保持数据的最终一致性。引入时间窗口概念
在分布式系统中,我们往往追求的是可用性,它的重要性比一致性要高,那么如何实现高可用,这里又有一个理论,就是 BASE 理论,它给 CAP 理论做了进一步的扩充。
- BASE 理论 BASE 理论指出:
Basically Available(基本可用) Soft state(软状态) Eventually consistent(最终一致性) BASE 理论是对 CAP 中的一致性和可用性进行一个权衡的结果,理论的核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性。
- 水平扩展/垂直扩展 水平扩展 Scale Out 通过增加更多的服务器或者程序实例来分散负载,从而提升存储能力和计算能力。另外,搜索公众号编程技术圈后台回复“商城”,获取一份惊喜礼包。
垂直扩展 Scale Up 提升单机处理能力。
垂直扩展的方式又有两种:
(1)增强单机硬件性能,例如:增加 CPU 核数如 32 核,升级更好的网卡如万兆,升级更好的硬盘如 SSD,扩充硬盘容量如 2T,扩充系统内存如 128G; (2)提升单机软件或者架构性能,例如:使用 Cache 来减少 IO 次数,使用异步来增加单服务吞吐量,使用无锁数据结构来减少响应时间;
平行扩容 与水平扩展类似。集群服务器中的节点均为平行对等节点,当需要扩容时,可以通过添加更多节点以提高集群的服务能力。一般来说服务器中关键路径(如服务器中的登录、支付、核心业务逻辑等)都需要支持运行时动态平行扩容。
弹性扩容 指对部署的集群进行动态在线扩容。弹性扩容系统可以根据实际业务环境按照一定策略自动地添加更多的节点(包括存储节点、计算节点、网络节点)来增加系统容量、提高系统性能或者增强系统可靠性,或者同时完成这三个目标。
状态同步/帧同步 状态同步:状态同步是指服务器负责计算全部的游戏逻辑,并且广播这些计算的结果,客户端仅仅负责发送玩家的操作,以及表现收到的游戏结果。
特征:状态同步安全性高,逻辑更新方便,断线重连快,但是开发效率较低,网络流量随游戏复杂度增加,服务器需要承载更大压力。
帧同步:服务端只转发消息,不做任何逻辑处理,各客户端每秒帧数一致,在每一帧都处理同样的输入数据。
特征:帧同步需要保证系统在相同的输入下,要有相同的输出。帧同步开发效率高,流量消耗低而且稳定,对服务器的压力非常小。但是网络要求高,断线重连时间长,客户端计算压力大。
网络通信
连接池 预先建立一个连接缓冲池,并提供一套连接使用、分配、管理策略,使得该连接池中的连接可以得到高效、安全的复用,避免了连接频繁建立、关闭的开销。
断线重连 由于网络波动造成用户间歇性的断开与服务器的连接,待网络恢复之后服务器尝试将用户连接到上次断开时的状态和数据。
会话保持 会话保持是指在负载均衡器上的一种机制,可以识别客户端与服务器之间交互过程的关连性,在作负载均衡的同时还保证一系列相关连的访问请求都会分配到一台机器上。用人话来表述就是:在一次会话过程中发起的多个请求都会落到同一台机器上。
长连接/短连接 通常是指 TCP 的长连接和短连接。长连接就是建立 TCP 连接后,一直保持这个连接,一般会中间彼此发送心跳来确认对应的存在,中间会做多次业务数据传输,一般不会主动断开连接。短连接一般指建立连接后,执行一次事务后(如:http 请求),然后就关掉这个连接。
流量控制/拥塞控制 流量控制防止发送方发的太快,耗尽接收方的资源,从而使接收方来不及处理。
拥塞控制防止发送方发的太快,使得网络来不及处理产生拥塞,进而引起这部分乃至整个网络性能下降的现象,严重时甚至会导致网络通信业务陷入停顿。
惊群效应 惊群效应也有人叫做雷鸣群体效应,不过叫什么,简言之,惊群现象就是多进程(多线程)在同时阻塞等待同一个事件的时候(休眠状态),如果等待的这个事件发生,那么他就会唤醒等待的所有进程(或者线程),但是最终却只可能有一个进程(线程)获得这个时间的“控制权”,对该事件进行处理,而其他进程(线程)获取“控制权”失败,只能重新进入休眠状态,这种现象和性能浪费就叫做惊群。
NAT NAT(Network Address Translation,网络地址转换),就是替换 IP 报文头部的地址信息。NAT 通常部署在一个组织的网络出口位置,通过将内部网络 IP 地址替换为出口的 IP 地址提供公网可达性和上层协议的连接能力。
故障异常
宕机 宕机,一般情况下指的就是计算机主机出现意外故障而死机。其次,一些服务器例如数据库死锁也可以称为宕机,一些服务器的某些服务挂掉了,就可以这么说。
coredump 当程序出错而异常中断时,OS 会把程序工作的当前状态存储成一个 coredunmp 文件。通常情况下 coredump 文件包含了程序运行时的内存,寄存器状态,堆栈指针,内存管理信息等。
缓存穿透/击穿/雪崩 缓存穿透:缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,进而给数据库带来压力。
缓存击穿:缓存击穿是指热点 key 在某个时间点过期的时候,而恰好在这个时间点对这个 Key 有大量的并发请求过来,从而大量的请求打到 db。
缓存雪崩:缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至 down 机。
与缓存击穿不同的是:存击穿是热点 key 失效,缓存雪崩是大量的 key 同时失效。
- 500/501/502/503/504/505 500 Internal Server Error:内部服务错误,一般是服务器遇到意外情况,而无法完成请求。可能原因:
1、程序错误,例如:ASP 或者 PHP 语法错误;
2、高并发导致,系统资源限制不能打开过多的文件所致。
501 Not implemented:服务器不理解或不支持请求的 HTTP 请求。
502 Bad Gateway:WEB 服务器故障,可能是由于程序进程不够,请求的 php-fpm 已经执行,但是由于某种原因而没有执行完毕,最终导致 php-fpm 进程终止。可能原因:
1、Nginx 服务器,php-cgi 进程数不够用;
2、PHP 执行时间过长;
3、php-cgi 进程死掉;
503 Service Unavailable:服务器目前无法使用。系统维护服务器暂时的无法处理客户端的请求,这只是暂时状态。可以联系下服务器提供商。
504 Gateway Timeout:服务器 504 错误表示超时,是指客户端所发出的请求没有到达网关,请求没有到可以执行的 php-fpm,一般是与 nginx.conf 的配置有关。
505 HTTP Version Not Supported:服务器不支持请求中所用的 HTTP 协议版本。(HTTP 版本不受支持)
除了 500 错误可能是程序语言错误,其余的报错,都大概可以理解为服务器或者服务器配置出现问题。
- 内存溢出/内存泄漏 内存溢出:内存溢出(Out Of Memory)指程序申请内存时,没有足够的内存供申请者使用,或者说,给了你一块存储 int 类型数据的存储空间,但是你却存储 long 类型的数据,那么结果就是内存不够用,此时就会报错 OOM,即所谓的内存溢出。
内存泄漏:内存泄漏(Memory Leak)指程序中己动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。
句柄泄漏 句柄泄漏是进程在调用系统文件之后,没有释放已经打开的文件句柄。一般句柄泄漏后的现象是,机器变慢,CPU 飙升,出现句柄泄漏的 cgi 或 server 的 CPU 使用率增加。
死锁 死锁是指两个或两个以上的线程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都抑制处于阻塞状态并无法进行下去,此时称系统处于死锁状态或系统产生了死锁。
软中断/硬中断 硬中断:我们通常所说的中断指的是硬中断(hardirq)。
主要是用来通知操作系统系统外设状态的变化。
软中断:1、通常是硬中断服务程序对内核的中断;2、为了满足实时系统的要求,中断处理应该是越快越好。
linux 为了实现这个特点,当中断发生的时候,硬中断处理那些短时间就可以完成的工作,而将那些处理事件比较长的工作,放到中断之后来完成,也就是软中断(softirq)来完成。
毛刺 在短暂的某一刻,服务器性能指标(如流量、磁盘 IO、CPU 使用率等)远大于该时刻前后时间段。毛刺的出现代表这服务器资源利用不均匀,不充分,容易诱发其他更严重的问题。
重放攻击 攻击者发送一个目的主机已接收过的包,来达到欺骗系统的目的,主要用于身份认证过程,破坏认证的正确性。它是一种攻击类型,这种攻击会不断恶意或欺诈性地重复一个有效的数据传输,重放攻击可以由发起者,也可以由拦截并重发该数据的敌方进行。攻击者利用网络监听或者其他方式盗取认证凭据,之后再把它重新发给认证服务器。
网络孤岛 网络孤岛指集群环境中,部分机器与整个集群失去网络连接,分裂为一个小集群并且发生数据不一致的状况。
数据倾斜 对于集群系统,一般缓存是分布式的,即不同节点负责一定范围的缓存数据。我们把缓存数据分散度不够,导致大量的缓存数据集中到了一台或者几台服务节点上,称为数据倾斜。一般来说数据倾斜是由于负载均衡实施的效果不好引起的。
脑裂 脑裂是指在集群系统中,部分节点之间网络不可达而引起的系统分裂,不同分裂的小集群会按照各自的状态提供服务,原本的集群会同时存在不一致的反应,造成节点之间互相争抢资源,系统混乱,数据损坏。
监控告警
- 服务监控 服务监控主要目的在服务出现问题或者快要出现问题时能够准确快速地发现以减小影响范围。服务监控一般有多种手段,按层次可划分为:
系统层(CPU、网络状态、IO、机器负载等) 应用层(进程状态、错误日志、吞吐量等) 业务层(服务/接口的错误码、响应时间) 用户层(用户行为、舆情监控、前端埋点) 2. 全链路监控 服务拨测:服务拨测是探测服务(应用)可用性的监控方式,通过拨测节点对目标服务进行周期性探测,主要通过可用性和响应时间来度量,拨测节点通常有异地多个。
节点探测:节点探测是用来发现和追踪不同的机房(数据中心)节点之间网络可用性和通畅性的监控方式,主要通过响应时间、丢包率、跳数来度量,探测方法一般是 ping、mtr 或其他私有协议。
告警过滤:对某些可预知的告警进行过滤,不进入告警统计的数据,如少量爬虫访问导致的 http 响应 500 错误,业务系统自定义异常信息等。
告警去重:当一个告警通知负责人后,在这个告警恢复之前,不会继续收到相同的告警。
告警抑制:为了减少由于系统抖动带来的干扰,还需要实现抑制,例如服务器瞬间高负载,可能是正常的,只有持续一段时间的高负载才需要得到重视。
告警恢复:开发/运维人员不仅需要收到告警通知,还需要收到故障消除告警恢复正常的通知。
告警合并:对同一时刻产生的多条相同告警进行合并,如某个微服务集群同一时刻出现多个子服务负载过高的告警,需要合并成为一条告警。
告警收敛:有时某个告警产生时,往往会伴随着其它告警。这时可以只对根本原因产生告警,其它告警收敛为子告警一并发送通知。如云服务器出现 CPU 负载告警时往往伴随其搭载的所有系统的可用性告警。
故障自愈:实时发现告警,预诊断分析,自动恢复故障,并打通周边系统实现整个流程的闭环。
服务治理
微服务 微服务架构是一种架构模式,它提倡将单一应用程序划分成一组小的服务,服务之间相互协调、互相配合,为用户提供最终价值。每个服务运行在其独立的进程中,服务和服务之间采用轻量级的通信机制相互沟通(通常是基于 HTTP 的 Restful API).每个服务都围绕着具体的业务进行构建,并且能够被独立的部署到生产环境、类生产环境等。
服务发现 服务发现是指使用一个注册中心来记录分布式系统中的全部服务的信息,以便其他服务能够快速的找到这些已注册的服务。服务发现是支撑大规模 SOA 和微服务架构的核心模块,它应该尽量做到高可用。
流量削峰 如果观看抽奖或秒杀系统的请求监控曲线,你就会发现这类系统在活动开放的时间段内会出现一个波峰,而在活动未开放时,系统的请求量、机器负载一般都是比较平稳的。为了节省机器资源,我们不可能时时都提供最大化的资源能力来支持短时间的高峰请求。所以需要使用一些技术手段,来削弱瞬时的请求高峰,让系统吞吐量在高峰请求下保持可控。削峰也可用于消除毛刺,使服务器资源利用更加均衡和充分。常见的削峰策略有队列,限频,分层过滤,多级缓存等。
版本兼容 在升级版本的过程中,需要考虑升级版本后,新的数据结构是否能够理解和解析旧数据,新修改的协议是否能够理解旧的协议以及做出预期内合适的处理。这就需要在服务设计过程中做好版本兼容。
过载保护 过载是指当前负载已经超过了系统的最大处理能力,过载的出现,会导致部分服务不可用,如果处置不当,极有可能引起服务完全不可用,乃至雪崩。过载保护正是针对这种异常情况做的措施,防止出现服务完全不可用的现象。
服务熔断 服务熔断的作用类似于我们家用的保险丝,当某服务出现不可用或响应超时的情况时,为了防止整个系统出现雪崩,暂时停止对该服务的调用。
服务降级 服务降级是当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略的降级,以此释放服务器资源以保证核心任务的正常运行。降级往往会指定不同的级别,面临不同的异常等级执行不同的处理。另外,搜索公众号 Java 架构师技术后台回复“Spring”,获取一份惊喜礼包。
根据服务方式:可以拒接服务,可以延迟服务,也有时候可以随机服务。
根据服务范围:可以砍掉某个功能,也可以砍掉某些模块。
总之服务降级需要根据不同的业务需求采用不同的降级策略。主要的目的就是服务虽然有损但是总比没有好。
- 熔断 VS 降级 相同点:目标一致,都是从可用性和可靠性出发,为了防止系统崩溃;用户体验类似,最终都让用户体验到的是某些功能暂时不可用;
不同点:触发原因不同,服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑;
服务限流 限流可以认为服务降级的一种,限流就是限制系统的输入和输出流量已达到保护系统的目的。一般来说系统的吞吐量是可以被测算的,为了保证系统的稳定运行,一旦达到的需要限制的阈值,就需要限制流量并采取一些措施以完成限制流量的目的。比如:延迟处理,拒绝处理,或者部分拒绝处理等等。
故障屏蔽 将故障机器从集群剔除,以保证新的请求不会分发到故障机器。
测试方法
- 黑盒/白盒测试 黑盒测试不考虑程序内部结构和逻辑结构,主要是用来测试系统的功能是否满足需求规格说明书。一般会有一个输入值,一个输入值,和期望值做比较。
白盒测试主要应用在单元测试阶段,主要是对代码级的测试,针对程序内部逻辑结构,测试手段有:语句覆盖、判定覆盖、条件覆盖、路径覆盖、条件组合覆盖
- 单元/集成/系统/验收测试 软件测试一般分为 4 个阶段:单元测试、集成测试、系统测试、验收测试。
单元测试:单元测试是对软件中的最小可验证单元进行检查和验证,如一个模块、一个过程、一个方法等。单元测试粒度最小,一般由开发小组采用白盒方式来测试,主要测试单元是否符合“设计”。
集成测试:集成测试也叫做组装测试,通常在单元测试的基础上,将所有的程序模块进行有序的、递增的测试。集成测试界于单元测试和系统测试之间,起到“桥梁作用”,一般由开发小组采用白盒加黑盒的方式来测试,既验证“设计”,又验证“需求”。
系统测试:系统测试时将经过集成测试的软件,作为计算机系统的一部分,与系统中其他部分结合起来,在实际运行环境下进行一系列严格有效的测试,以发现软件潜在的问题,保证系统的正常运行。系统测试的粒度最大,一般由独立测试小组采用黑盒方式来测试,主要测试系统是否符合“需求规格说明书”。
验收测试:验收测试也称交付测试,是针对用户需求、业务流程进行的正式的测试,以确定系统是否满足验收标准,由用户、客户或其他授权机构决定是否接受系统。验收测试与系统测试相似,主要区别是测试人员不同,验收测试由用户执行。
回归测试 当发现并修改缺陷后,或在软件中添加新的功能后,重新测试。用来检查被发现的缺陷是否被改正,并且所做的修改没有引发新的问题。
冒烟测试 这一术语源自硬件行业。对一个硬件或硬件组件进行更改或修复后,直接给设备加电。如果没有冒烟,则该组件就通过了测试。在软件中,“冒烟测试”这一术语描述的是在将代码更改嵌入到产品的源树中之前对这些更改进行验证的过程。
冒烟测试是在软件开发过程中的一种针对软件版本包的快速基本功能验证策略,是对软件基本功能进行确认验证的手段,并非对软件版本包的深入测试。
比如:对于一个登录系统的冒烟测试,我们只需测试输入正确的用户名、密码,验证登录这一个核心功能点,至于输入框、特殊字符等,可以在冒烟测试之后进行。
- 性能测试 性能测试是通过自动化的测试工具模拟多种正常、峰值以及异常负载条件来对系统的各项性能指标进行测试。负载测试和压力测试都属于性能测试,两者可以结合进行。
通过负载测试,确定在各种工作负载下系统的性能,目标是测试当负载逐渐增加时,系统各项性能指标的变化情况。
压力测试是通过确定一个系统的瓶颈或者不能接受的性能点,来获得系统能提供的最大服务级别的测试。
基准测试 基准测试(Benchmark)也是一种性能测试方式,用来测量机器的硬件最高实际运行性能,以及软件优化的性能提升效果, 同时也可以用来识别某段代码的 CPU 或者内存效率问题. 许多开发人员会用基准测试来测试不同的并发模式, 或者用基准测试来辅助配置工作池的数量, 以保证能最大化系统的吞吐量.
A/B 测试 A/B 测试,是用两组及以上随机分配的、数量相似的样本进行对比,如果实验组和对比组的实验结果相比,在目标指标上具有统计显著性,那就可以说明实验组的功能可以导致你想要的结果,从而帮你验证假设或者做出产品决定。
代码覆盖测试 代码覆盖(Code coverage)是软件测试中的一种度量,描述程式中源代码被测试的比例和程度,所得比例称为代码覆盖率。在做单元测试时,代码覆盖率常常被拿来作为衡量测试好坏的指标,甚至,用代码覆盖率来考核测试任务完成情况,比如,代码覆盖率必须达到 80%或 90%。于是乎,测试人员费尽心思设计案例覆盖代码。
发布部署
- DEV/PRO/FAT/UAT DEV(Development environment):开发环境,用于开发人员调试使用,版本变化较大。
FAT(Feature Acceptance Test environment):功能验收测试环境,用于软件测试人员测试使用。
UAT(User Acceptance Test environment):用户验收测试环境,用于生产环境下的功能验证,可作为预发布环境。
PRO(Production environment):生产环境,正式线上环境。
灰度发布 灰度发布是指在升级版本过程中,通过分区控制,白名单控制等方式对一部分用户先升级产品特性,而其余用户则保持不变,当一段时间后升级产品特性的用户没有反馈问题,就逐步扩大范围,最终向所有用户开放新版本特性,灰度发布可以保证整体系统的稳定,在初始灰度的时候就可以发现、修改问题,以保证其影响度。
回滚 (Rollback) 指的是程序或数据处理错误时,将程序或数据恢复到上一次正确状态(或者是上一个稳定版本)的行为。
联机分析处理(OLAP,On-line Analytical Processing),数据量大,DML少。使用数据仓库模板
联机事务处理(OLTP,On-line Transaction Processing),数据量少,DML频繁,并行事务处理多,但是一般都很短。使用一般用途或事务处理模板。
决策支持系统(DDS,Decision support system),典型的操作是全表扫描,长查询,长事务,但是一般事务的个数很少,往往是一个事务独占系统。
时间轮算法
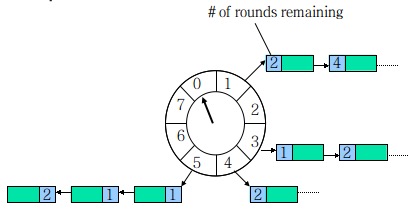 开源实现 Netty的HashedWheelTimer Guava的Ticker
开源实现 Netty的HashedWheelTimer Guava的Ticker ddd 领域驱动设计
mvn 包搜索
多线程
死锁的产生通常涉及以下四个必要条件:
互斥条件(Mutual Exclusion):至少有一个资源必须被一个线程独占使用,即在一段时间内只能由一个线程持有。
请求与保持条件(Hold and Wait):一个线程在持有某个资源的同时,又请求获取其他线程持有的资源。
不可剥夺条件(No Preemption):已经分配给一个线程的资源不能被强制性地剥夺,只能由持有者显式地释放。
循环等待条件(Circular Wait):存在一个线程资源的循环链,每个线程都在等待下一个线程所持有的资源。
当这四个条件同时满足时,就会发生死锁。
阅读
https://doocs.gitee.io/source-code-hunter
juc
Semaphore 信号量
Semaphore 属于共享锁, 控制同一时间并发线程的数目。能够完成对于信号量的控制,可以控制某个资源可被同时访问的个数。
Semaphore 的 PV 操作的加减计数器操作都是原子性的,可以直接在多线程环境下使用
Semaphore 可以用来控制同时访问特定资源的线程数量 底层依赖 AQS 的状态 State
semaphore 常用于仅能提供有限访问的资源,比如:数据库连接数。
CountDownLatch 线程计数器
等待多个线程全部执行完,再执行某个任务
CyclicBarrier 栅栏屏障 循环屏障
栅栏屏障,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续运行。
CyclicBarrier 可以用于多线程计算数据,最后合并计算结果的场景
AQS(AbstractQueuedSynchronizer 类
乐观锁 悲观锁
悲观锁 认为在使用数据的时候一定有别的线程来修改数据,所以在获取数据的时候需要先加锁,确保数据不会被其他线程所修改。
synchronized lock 行锁 表锁 读锁(共享锁) 写锁(排他锁)
乐观锁
认为在使用数据的时候别的线程不会修改。只有在想要更新数据的数据的时候,才去检查是否有锁。
cas(Compare And Swap 比较与交换) 算法 版本号
Phaser(阶段协同器)是一个Java实现的并发工具类,用于协调多个线程的执行
Phaser可以被视为CyclicBarrier和CountDownLatch的进化版,它能够自适应地调整并发线程数,
可以动态地增加或减少参与线程的数量
Phaser特别适合使用在重复执行或者重用的情况。
TransferQueue 消费者生产者
java共享内存 可以使用共享变量来实现共享内存。共享变量是多个线程可以访问的变量,可以通过读取和写入共享变量来实现数据共享和通信
线程之间的通信由 Java 内存模型(本文简称为 JMM)控制
AQS 分为独占锁和共享锁
ReentrantLock(独占锁):可重入,可中断,可以是公平锁也可以是非公平锁,非公平锁就是会通过两次CAS去抢占锁,公平锁会按队列顺序排队
Semaphore(信号量):设定一个信号量,当调用acquire()时判断是否还有信号,有就获取一个信号量,没有就阻塞等待其他线程释放信号量,当调用release()时释放一个信号量,唤醒阻塞线程。
应用场景:允许多个线程访问某个临界资源时,如上下车,买卖票
CountDownLatch(倒计数器):给计数器设置一个初始值,当调用CountDown()时计数器减一,当调用await() 时判断计数器是否归0,不为0就阻塞,直到计数器为0。
应用场景:启动一个服务时,主线程需要等待多个组件加载完毕,之后再继续执行
CyclicBarrier(循环栅栏):给计数器设置一个目标值,当调用await() 时会计数+1并判断计数器是否达到目标值,未达到就阻塞,直到计数器达到目标值
应用场景:多线程计算数据,最后合并计算结果的应用场景
为啥会有双重检测机制?
第一层 if (instance == null)是为了减少线程对同步锁锁的竞争
第二层if(instance==nul)是保证单例
volatile禁止指令重排序
动态代理分为两类 : 一类是基于接口 , 一类是基于类
基于接口的动态代理:JDK 动态代理。
基于类的动态代理:CGLIB 动态代理。
现在用的比较多的是 Javassist 来生成动态代理。
java的四种锁机制
互斥锁 synchronized
读写锁 ReentrantReadWriteLock
条件锁 Condition
分布式锁 Redlock Zookeeper
使用 Volatile 一般用于 状态标记量 和 单例模式的双检锁
++i i++
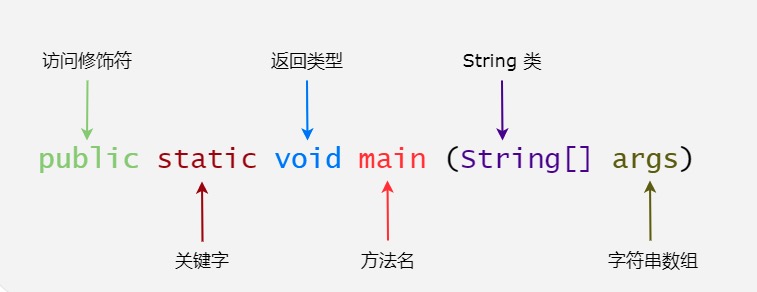
java
1、什么是左值和右值?
左值就是出现在表达式左边的值(等号左边),可以被改变,他是存储数据值的那块内存的地址,也称为变量的地址;
右值是指存储在某内存地址中的数据,也称为变量的数据。
左值可以作为右值,但右值不可以是左值。
因此也只有左值才能被取地址。
i++不能作为左值
i++返回的是一个临时变量,函数返回后不能被寻址得到,它只是一个数据值,而非地址,因此不能作为左值多线程数据同步常用
在 Java 中的多线程数据同步的场景,常会出现:
关键字 volatile 用于刷新数据缓存 禁用 cpu 缓存 关键字 synchronized 可重入锁/读写锁 java.util.concurrent.locks._ 容器同步包装,如 Collections.synchronizedXxx() 新的线程安全容器,如 CopyOnWriteArrayList/ConcurrentHashMap 阻塞队列 java.util.concurrent.BlockingQueue 原子类 java.util.concurrent.atomic._ 以及 JUC 中其他工具诸如 CountDownLatch/Exchanger/FutureTask 等角色。 其中 volatile 关键字用于刷新数据缓存,即保证在 A 线程修改某数据后,B 线程中可见,这里面涉及的线程缓存和指令重排因篇幅原因不在本文探讨范围之内。而不论是 synchronized 关键字下的对象锁,还是基于同步器 AbstractQueuedSynchronizer 的 Lock 实现者们,它们都属于悲观锁。而在同步容器包装、新的线程程安全容器和阻塞队列中都使用的是悲观锁;只是各类的内部使用不同的 Lock 实现类和 JUC 工具,另外不同容器在加锁粒度和加锁策略上分别做了处理和优化。
这里值得一说的,也是本文聚焦的重点则是原子类,即 java.util.concurrent.atomic.* 包下的几个类库诸如 AtomicBoolean/AtomicInteger/AtomicReference
ThreadLocal 每个线程对变量访问时访问的是线程自己的本地变量
多线程杂项
可见性
原子性
有序性
缓存带来了可见性问题。
线程切换带来了原子性问题。
编译优化带来了有序性问题。
InheritableThreadLocal 解决子线程中获取到主线程设置的值mvn
mvn clean package -e -P dev -DskipTests -T 1C -Dmaven.compile.fork=true --settings settings.xml
mvn spring-boot:run '-Dspring-boot.run.jvmArguments="-Dserver.port=8080 -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=5005 -Dspring-boot.run.profiles=dev -noverify -server -Dpagehelper.reasonable=true -Dspring.mvc.servlet.load-on-startup=1 -Dspring.mvc.jsp.enabled=false -Dserver.compression.enabled=true "'
mvn spring-boot:run '-Dspring-boot.run.jvmArguments=" -Dspring.mvc.jsp.enabled=false -Dpagehelper.reasonable=true -Dspring.mvc.servlet.load-on-startup=1 -Dspring.quartz.auto-startup=false"'
mvn dependency:tree -Dverbose -Dincludes="com.baomidou:mybatis-plus"
-Dpagehelper.reasonable=true -Dspring.mvc.servlet.load-on-startup=1 -Dspring.mvc.jsp.enabled=false -Dserver.compression.enabled=true -Dspring.quartz.auto-startup=false -Djava.awt.headless=true
-noverify -XX:TieredStopAtLevel=1
spring-context-indexer
spring.main.lazy-initialization=true 有坑 pageHelper会有误切记~~
spring.mvc.jsp.enabled=false
-Djava.awt.headless=true
-XX:+UseShenandoahGC
-XX :+UseStringDeduplication
jvm
Java 线程同步底层就是监视锁Monitor
堆【线程共享】 :对象实例
方法区【线程共享】 :类信息、常量、静态变量、编译后的代码
栈 :局部变量、操作栈、动态链接、方法出口
程序计数器 :字节码的行号指示器
本地方法栈 :JVM使用到的native方法服务(java调用非java代码的接口)
Young Generation(新生代):分为:Eden区和Survivor区,Survivor区有分为大小相等的From Space和To Space。
Old Generation(老年代): Tenured区,当 Tenured区空间不够时, JVM 会在Tenured区进行 major collection。
Minor GC:新生代GC,指发生在新生代的垃圾收集动作,因为java对象大多都具备朝生夕死的特性,所以Minor GC非常频繁,一般回收速度也比较快。
Major GC:发生老年代的GC,对整个堆进行GC。出现Major GC,经常会伴随至少一次Minor GC(非绝对)。MajorGC的速度一般比minor GC慢10倍以上。
Full GC:整个虚拟机,包括永久区、新生区和老年区的回收。
JVM 区域总体分两类, heap 区和非 heap 区。 heap 区分:Eden Space(伊甸园)、Survivor Space (幸存者区)、Tenured Gen(老年代 - 养老区)。 非 heap 区又分:Code Cache (代码缓存区)、Perm Gen(永久代)、Jvm Stack (java 虚拟机栈)、Local Method Statck (本地方法栈)。
调用方法时传递的参数以及在调用中创建的临时变量都保存在栈(Stack)中,速度较快;其他变量,如静态变量、实例变量等,都在堆(Heap)中创建,速度较慢
Java 虚拟机规范规定的区域分为以下 5 个部分: 程序计数器(Program Counter Register):当前线程所执行的字节码的行号指示器,字节码解析器的工作是通过改变这个计数器的值,来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能,都需要依赖这个计数器来完成; Java 虚拟机栈(Java Virtual Machine Stacks):用于存储局部变量表、操作数栈、动态链接、方法出口等信息; 本地方法栈(Native Method Stack):与虚拟机栈的作用是一样的,只不过虚拟机栈是服务 Java 方法的,而本地方法栈是为虚拟机调用 Native 方法服务的; Java 堆(Java Heap):Java 虚拟机中内存最大的一块,是被所有线程共享的,几乎所有的对象实例都在这里分配内存; 方法区(Methed Area):用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译后的代码等数据
Bootstrap ClassLoader主要负责加载 <JAVA_HOME>/jre/lib 目录下的核心Java类,如java.lang等,我们前面说的到String类就是有这个类加载器来加载。
Extension ClassLoader主要负责加载 <JAVA_HOME>/jre/lib/ext 目录下的类文件,以及通过系统变量java.ext.dirs指定的其他目录中的类文件。
Application ClassLoader负责加载应用程序类路径(classpath)下的类文件,通常是通过-cp或-classpath指定的目录或JAR包。
自定义类加载器可以根据开发人员的实际需求加载不同来源的类文件,例如从网络、数据库等载入类。
spring-cloud
服务发现、配置中心—— Eureka nacos
负载均衡—— Ribbon
断路器—— Hystrix
服务网关—— Zuul gateway
分布式配置——Spring Cloud Config
服务间调用 Feign OpenFeign
链路追踪 Sleuth
流量治理 Sentinel
静态代码分析
soot wala
必备
https://refactoringguru.cn/design-patterns#intro-history
springboot cache
@Cacheable(value = "api-cache", key = "#root.methodName+T(com.alibaba.fastjson.JSON).toJSONString(#root.args)")mybatis
@Results(id = "userResult", value = {
@Result(property = "uid", column = "uid", id = true),
@Result(property = "username", column = "username"),
@Result(property = "reg", column = "uid", one = @One(select = "xx.xx.xx.xxx", fetchType = FetchType.EAGER)),
@Result(property = "userRole", column = "uid", one = @One(select = "xx.xx.xx.xxx", fetchType = FetchType.EAGER)),
@Result(property = "resource", column = "uid", many = @Many(select = "xx.xx.xx.xxxx", fetchType = FetchType.EAGER))
})@Value的用法及(“#{}“)与@Value(“${}“)的区别
1、@Value("#{}") Spring 表达式语言(简称SpEL)
SpEL 字面量:
整数:#{8}
小数:#{8.8}
科学计数法:#{1e4}
String:可以使用单引号或者双引号作为字符串的定界符号。
Boolean:#{true}
SpEL引用bean , 属性和方法:
引用其他对象:#{car}
引用其他对象的属性:#{car.brand}
调用其它方法 , 还可以链式操作:#{car.toString()}
调用静态方法静态属性:#{T(java.lang.Math).PI}
SpEL支持的运算符号:
算术运算符:+,-,*,/,%,^(加号还可以用作字符串连接)
比较运算符:< , > , == , >= , <= , lt , gt , eg , le , ge
逻辑运算符:and , or , not , |
if-else 运算符(类似三目运算符):?:(temary), ?:(Elvis)
正则表达式:#{admin.email matches ‘[a-zA-Z0-9._%±]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,4}’}
2.@Value(“true”) 直接赋值
3.@Value("${person.name}")加密数据模糊查询
https://open.taobao.com/docV3.htm?docId=106213&docType=1
java修饰符
访问修饰符:
public: 意味着代码对所有类可访问。
private: 意味着代码只能在声明的类内部访问。
default: 意味着代码只能在同一包中访问。修饰符 也可以称为 package-private 修饰符。
protected: 意味着代码在同一包和子类中可访问。修饰符允许子类访问父类中的成员,但不允许外部类访问。
非访问修饰符:
final: 意味着类不能被继承,属性和方法不能被重写。
static: 意味着属性和方法属于类,而不属于对象。 变量和方法也称为 类变量 和 类方法。
abstract: 意味着类不能用于创建对象,方法没有主体,必须由子类提供。类不能被实例化,只能被继承。
transient: 意味着在序列化包含它们的对象时,属性和方法将被跳过。变量不会被序列化。
synchronized: 意味着方法一次只能由一个线程访问。方法可以防止多个线程同时执行。
volatile: 意味着属性的值不会在本地线程缓存,总是从“主内存”读取。变量保证每次读取都将获取最新的值杂记
Java HashMap merge()
状态机优化
减少实例的尺寸: 在编写代码时,如果能够引用,就坚决不要拷贝;
如果能够复用,就坚决不要创新。
能够共享的资源,多使用不可变(immutable)的资源和禁止修改(unmodifiable) 的资源。
Map<String, Runnable> map = new HashMap<>();
map.put("condition", () -> { // do something });
map.get("condition").run();
yml
YAML 是一种标记语言,它可以很直观的展示数据序列化格式,可读性高。类似于 XML数据描述语言,语法比 XML 简单的很多。 YAML 数据结构通过缩进来表示,连续的项目通过减号来表示,键值对用冒号分隔,数组用中括号 [] 括起来,hash 用花括号 {} 括起来
YAML 支持的数据结构有三种 对象:键值对的集合,又称为映射(mapping)/ 哈希(hashes) / 字典(dictionary) 数组:一组按次序排列的值,又称为序列(sequence) / 列表(list) 纯量(scalars):单个的、不可再分的值
JDK内置工具使用
一、javah命令(C Header and Stub File Generator)
二、jps命令(Java Virtual Machine Process Status Tool)
Java程序在启动以后,会在Java.io.tmpdir指定的目录下,就是临时文件夹里,生成一个类似于hsperfdata_User的文件夹,这个文件夹里(在Linux中为/tmp/hsperfdata_{userName}/),有几个文件,名字就是Java进程的pid,因此列出当前运行的Java进程,只是把这个目录里的文件名列一下而已。至于系统的参数什么,就可以解析这几个文件获得
三、jstack命令(Java Stack Trace)
四、jstat命令(Java Virtual Machine Statistics Monitoring Tool)
五、jmap命令(Java Memory Map)
六、jinfo命令(Java Configuration Info)
七、jconsole命令(Java Monitoring and Management Console)
八、jvisualvm命令(Java Virtual Machine Monitoring, Troubleshooting, and Profiling Tool)
九、jhat命令(Java Heap Analyse Tool)
十、Jdb命令(The Java Debugger)
Springboot如何开发一个自定义Starter 1.创建Service 2.创建Properties 3.创建Autoonfiguration文件 // [!code focus] 4.配置spring.factories文件 5.pom引入package
日志追踪
import org.slf4j.MDC;
MDC.put("session_id", "xxxx");
%X{session_id}jdk动态代理
JDK 动态代理类使用步骤
定义一个接口及其实现类;
自定义InvocationHandler 并重写invoke方法,在 invoke 方法中我们会调用原生方法(被代理类的方法)并自定义一些处理逻辑;
通过 Proxy.newProxyInstance(ClassLoader loader,Class<?>[] interfaces,InvocationHandler h) 方法创建代理对象;设计模式
单例模式
getInstance() 方法中需要使用同步锁 synchronized (Singleton.class) 防止多线程同时进入造成 instance 被多次实例化
构造器私有使得外界无法通过构造器实例化Singleton类,要取得实例只能通过getInstance()方法
invoke方法的作用包括但不限于以下几个方面:
动态调用方法:invoke方法可以通过方法名和参数值来调用对象的方法,即使在编译时并不知道具体的方法。这对于实现动态调用、泛型编程等场景非常有用。
访问属性值:invoke方法可以通过属性名来获取或设置对象的属性值,即使在编译时并不知道具体的属性。这可以实现对对象的动态属性操作。
执行私有方法:invoke方法可以调用对象的私有方法,即使在正常情况下无法直接访问私有方法。这对于一些特殊需求,如测试私有方法的功能等场景非常有用。
动态代理:invoke方法可以被用于实现动态代理,即在运行时生成代理对象并在代理对象中调用实际对象的方法。这对于实现AOP(面向切面编程)等场景非常有用。
装饰器模式3点:
继承处理接口,提供构造函数,覆盖方法 (tips:可以嵌套)
责任链模式
next下一个需要处理的节点,关联链路 (tips:类似递归的感觉)
迭代器模式
hasNext() next()
中介者模式
统一到同一个地方集中处理
适配器模式
类适配 对象适配
1. **创建型模式**:
- **工厂方法模式**:提供一个创建对象的接口,但由子类决定要实例化的类是哪一个。
- **抽象工厂模式**:提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们的具体类。
- **单例模式**:保证一个类只有一个实例,并提供一个全局访问点。
- **建造者模式**:将复杂对象的构建与其表示分离,使得同样的构建过程可以创建不同的表示。
- **原型模式**:通过复制已有对象来创建新对象。
2. **结构型模式**:
- **适配器模式**:使两个不兼容的接口能够协同工作。
- **装饰器模式**:动态地给一个对象添加一些额外的职责。
- **代理模式**:为其他对象提供一种代理以控制对这个对象的访问。
- **外观模式**:提供一个统一的接口,用来访问子系统中的多个接口。
- **桥接模式**:将抽象部分与它的实现部分分离,使它们都可以独立地变化。
- **组合模式**:允许你将对象组合成树形结构来表现“整体/部分”层次结构。
- **享元模式**:运用共享技术有效地支持大量细粒度的对象。
3. **行为型模式**:
- **策略模式**:定义一系列的算法,并将每一个算法封装起来,使它们可以互相替换。
- **模板方法模式**:定义一个操作中的算法骨架,而将一些步骤延迟到子类中。
- **观察者模式**:定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都会得到通知并被自动更新。
- **责任链模式**:使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合。
- **访问者模式**:在不改变集合元素的前提下,为集合中的元素增加新的操作。
- **中介者模式**:定义一个中介对象来简化原本复杂的对象间交互。
- **迭代器模式**:提供一种方法顺序访问聚合对象的元素,而又不暴露其底层表示。
- **命令模式**:将请求封装为一个对象,从而使你可用不同的请求对客户进行参数化。
- **状态模式**:允许对象在其内部状态改变时改变它的行为,对象看起来似乎修改了它的类。
- **备忘录模式**:在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,以便以后恢复对象的状态。
- **解释器模式**:给定一种语言,定义它的文法表示,并提供一个解释器来实现该语言的文法。task
- [] spring boot
- [] spring cloud (eureka,ribbon,hystrix,feign,zuul/gateway,config ,bus,consul)
- [] mysql
- [] mybatis
- [] monogodb
- [] rabbitmq
- [] kafka
- [] zookeeper
- [] nacos
- [] dubbo
- [] es
- [] redis
- [] docker
- [] k8s
- [] netty
- [] nginx
- [] 多线程
- [] 高并发
- [] 高可用
- [] 高性能
- [] 分布式
- [] netty
- [] golang
- [] python
- [] 数据结构
- [] 算法
- [] 底层源码
- [] shardingjdbc
拓展
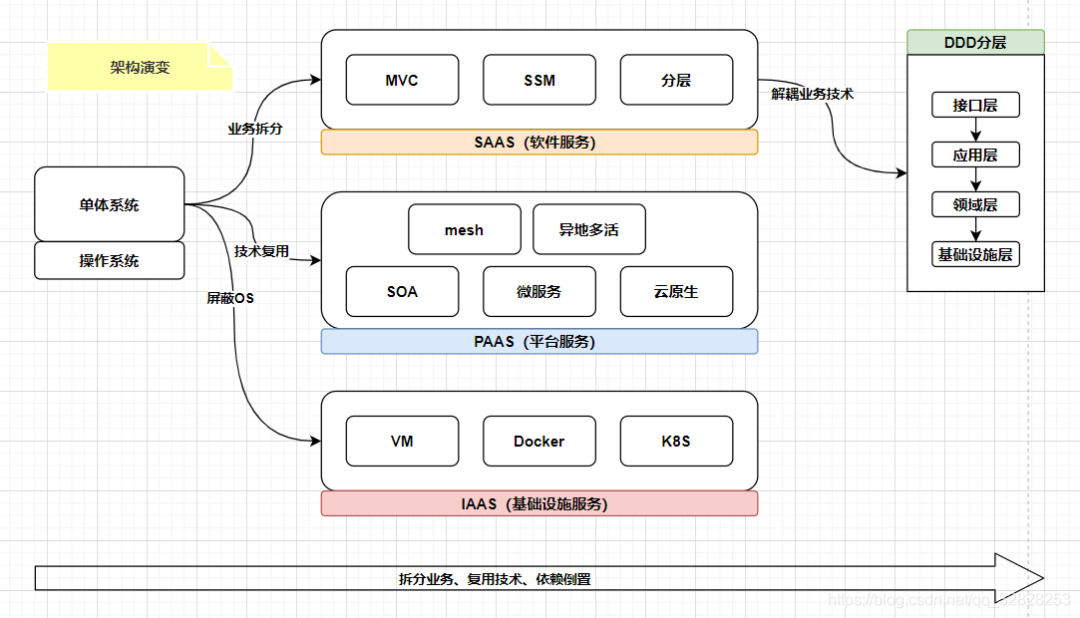
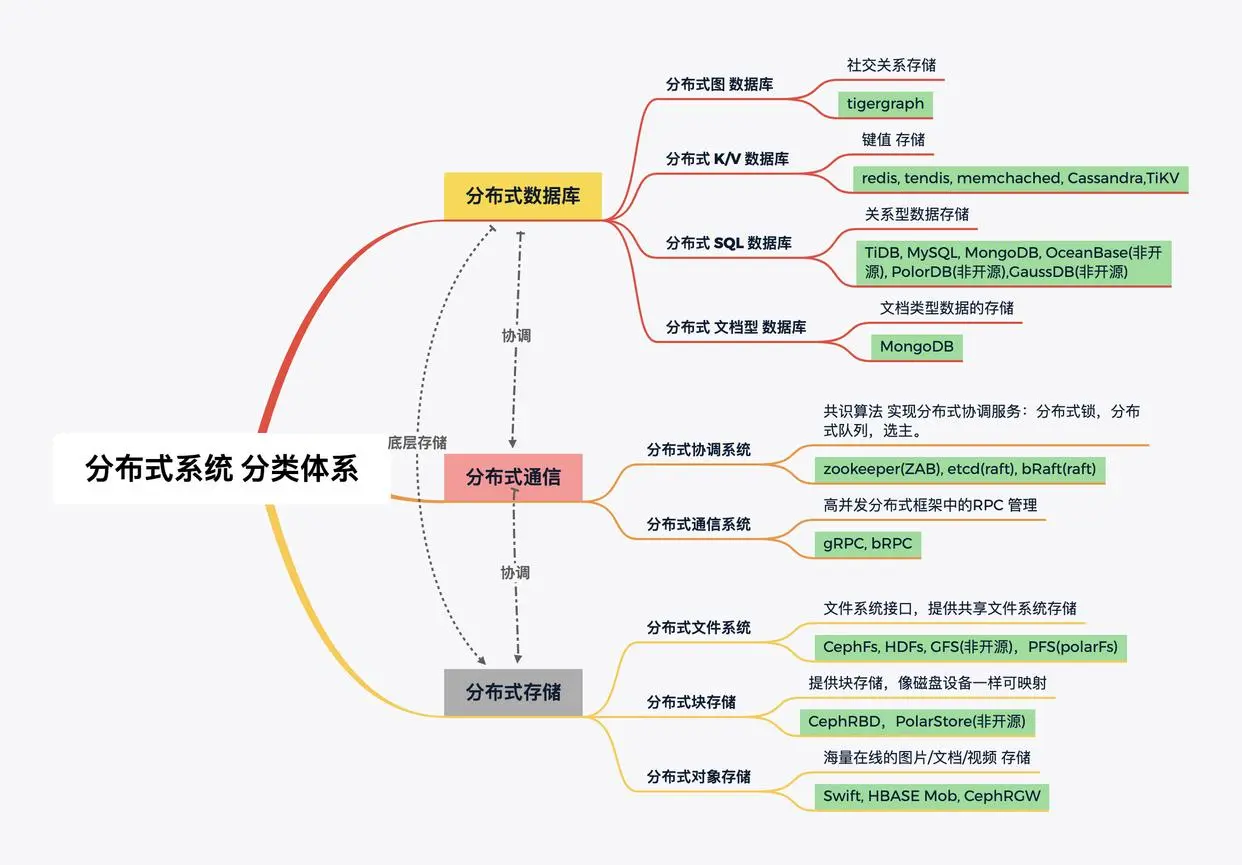


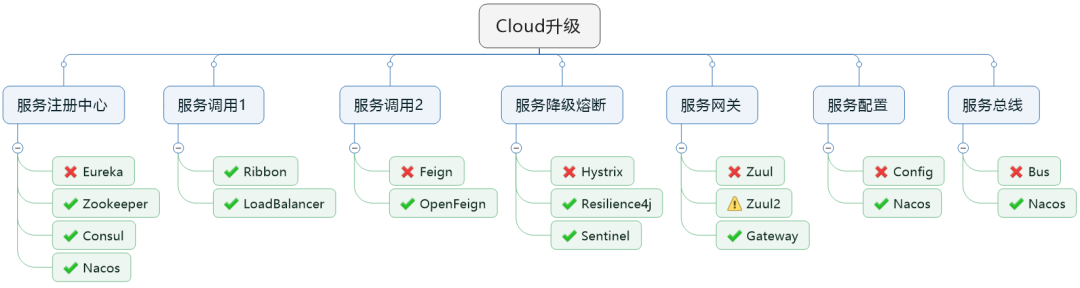
springboot自定义拓展
因为这时候spring容器还没被初始化,所以想要自己的扩展的生效,有以下三种方式:
在启动类中用springApplication.addInitializers(new TestApplicationContextInitializer())语句加入
配置文件配置context.initializer.classes=com.example.demo.TestApplicationContextInitializer
Spring SPI扩展,在spring.factories中加入org.springframework.context.ApplicationContextInitializer=com.example.demo.TestApplicationContextInitializer
openapi规范
分布式
分布式事务 seata tx-lcn
全局事务2pc(两段提交协议) 全局事务3pc(三段提交协议) 消息中间件 TCC事务模式 提供回滚接口 应用分布式数据库 使用分布式事务管理框架等
cp ap
cp 刚性事务
ap 柔性事务
数据一致性(consistency)、 服务可用性(availability)、 分区容错性(partition-tolerance) cp架构解决方案
dtp xa
ap架构解决方案
java元注解
@Retention:定义注解的保留策略,即注解在什么阶段可见。它可以是SOURCE(源码阶段),CLASS(编译时),或者RUNTIME(运行时)。
@Target:指定注解可以应用到哪些程序元素上,如类、方法、变量等。它使用ElementType枚举值来指定,例如ElementType.METHOD表示方法,ElementType.TYPE表示类或接口。
@Documented:指示是否将注解包含在生成的Javadoc中。
@Inherited:指示注解是否被子类继承。如果一个类被@Inherited注解,那么它的所有子类都将隐式具有这个注解,除非子类显式地添加了不同的注解。
@Repeatable:从Java 8开始引入,允许一个注解在同一位置重复出现多次。如果不使用@Repeatable,那么默认情况下一个注解在一个位置只能出现一次
jdbc连接过程
使用jdbc编程需要连接数据库,注册驱动和数据库信息
操作Connection,打开Statement对象
通过Statement对象执行SQL,返回结果到ResultSet对象
使用ResultSet读取数据,然后通过代码转化为具体的POJO对象
关闭数据库相关的资源
编程35种算法
线性搜索算法:通过逐个比较来查找给定值。
二分搜索算法:通过将搜索区间减半来快速查找有序数组中的元素。
插入排序算法:通过逐个地插入元素来对数组进行排序。
选择排序算法:通过选择最小(或最大)的元素来对数组进行排序。
冒泡排序算法:通过相邻元素的比较和交换来对数组进行排序。
归并排序算法:通过将数组分成较小的块并逐步合并它们来对数组进行排序。
快速排序算法:通过选择一个基准元素并将数组分成两个子数组来对数组进行排序。
堆排序算法:通过构建最大(或最小)堆来对数组进行排序。
计数排序算法:通过计算元素的出现次数来对数组进行排序。
桶排序算法:通过将元素分配到不同的桶中来对数组进行排序。
基数排序算法:通过将元素按照位数进行排序来对数组进行排序。
字符串匹配算法:通过查找模式在给定文本中的出现位置来进行字符串匹配。
广度优先搜索算法:通过遍历节点的邻居来搜索图的最短路径。
深度优先搜索算法:通过递归地遍历节点的邻居来搜索图的最短路径。
Dijkstra算法:通过计算节点之间的最短路径来搜索加权图。
Floyd-Warshall算法:通过计算所有节点之间的最短路径来搜索加权图。
贝尔曼-福特算法:通过计算从源节点到所有其他节点的最短路径来搜索加权图。
A*算法:通过启发式函数来搜索图的最短路径。
拓扑排序算法:通过确定图中节点之间的依赖关系来排序图的节点。
Kruskal算法:通过选择边来构建最小生成树。
Prim算法:通过选择节点来构建最小生成树。
最大流算法:通过在网络中查找最大流量路径来解决最大流问题。
最小割算法:通过在网络中查找最小割来解决最小割问题。
背包问题算法:通过动态规划来解决背包问题。
最长公共子序列算法:通过动态规划来查找两个序列的最长公共子序列。
最短公共超序列算法:通过动态规划来查找两个序列的最短公共超序列。
最长递增子序列算法:通过动态规划来查找给定序列的最长递增子序列。
最大子数组和算法:通过动态规划来查找给定数组的最大子数组和。
最优二叉搜索树算法:通过动态规划来构建最优二叉搜索树。
多重背包问题算法:通过动态规划来解决多重背包问题。
最大公约数算法:通过欧几里得算法来查找两个数的最大公约数。
最小公倍数算法:通过最大公约数算法来计算两个数的最小公倍数。
斐波那契数列算法:通过递归或动态规划来生成斐波那契数列。
快速幂算法:通过递归或迭代来计算幂。
回溯算法:通过尝试所有可能的解决方案来解决组合优化问题。
冒泡排序
快速排序
选择排序
插入排序
jwt
JWT(JSON Web Token)是一种用于在网络应用间安全传递声明(claim)的开放标准。
它由三部分组成:头部(Header)、载荷(Payload)和签名(Signature)
jvm
类加载子系统 bootstrap class loader
extention class loader
app class loader
运行时数据区(内存结构)
局部变量 栈
成员变量 堆
静态变量 方法区
执行引擎
并发、并行、串行
并发: 多个事件同一时间间隔发生 多个任务会相互干扰,同一时间点只有一个任务运行,交替执行
并行:多个事件同一时刻发生 多个任务互不干扰,在同一时间点共同执行,在时间上是重叠的
串行: 按顺序执行 在同一时间点只有一个任务运行,在时间上不可能重叠,任务挨个运行
为什么jdk8用元空间数据结构用来替代永久代?
字符串存在永久代中,容易出现性能问题和内存溢出。
类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出。
永久代会为GC带来不必要的复杂度,并且回收效率偏低。
高并发ConcurrentHashMap 1.8的原理
数组+链表+红黑树的实现方式来设计,内部大量采用CAS操作
synchronized+CAS+HashEntry+红黑树。
1.数据结构:取消了Segment分段锁的数据结构,取而代之的是数组+链表+红黑树的结构。
2.保证线程安全机制:JDK1.7采用segment的分段锁机制实现线程安全,其中segment继承自ReentrantLock。JDK1.8采用CAS+Synchronized保证线程安全。
3.锁的粒度:原来是对需要进行数据操作的Segment加锁,现调整为对每个数组元素加锁(Node)。
4.链表转化为红黑树:定位结点的hash算法简化会带来弊端,Hash冲突加剧,因此在链表节点数量大于8时,会将链表转化为红黑树进行存储。
5.查询时间复杂度:从原来的遍历链表O(n),变成遍历红黑树O(logN)
mysql ssl
生成truststore文件
keytool -importcert -alias Cacert -file ca.pem -keystore mysql-truststore -storepass xxxxx
生成keystore文件
keytool -importkeystore -srckeystore mysql-truststore -destkeystore mysql-keystore -deststoretype pkcs12
mysql-ssl: true&verifyServerCertificate=true&requireSSL=true&clientCertificateKeyStoreUrl=classpath:mysql_ssl/mysql-keystore&clientCertificateKeyStorePassword=123456Ab&trustCertificateKeyStoreUrl=classpath:mysql_ssl/mysql-truststore&trustCertificateKeyStorePassword=123456Ab
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.1.2:3306/database?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&useSSL=${mysql-ssl}
username: root
password: 123456Ab
spring.datasource.url=jdbc:mysql://localhost:3306/db_name?useSSL=true&requireSSL=true&verifyServerCertificate=true&trustCertificateKeyStoreUrl=file:/path/to/your/certificate.crt spring.datasource.username=db_username spring.datasource.password=db_passwordembedded
<dependency>
<groupId>com.github.kstyrc</groupId>
<artifactId>embedded-redis</artifactId>
<version>0.6</version>
</dependency>函数式编程妙用
/**
* 确认数据库字段值有效(通用)
*
* @param <V> 待验证值的类型
* @param valueToCheck 待验证的值
* @param columnExtractor 实体类属性提取函数
* @param queryExecutor 单条数据查询执行器
* @param errorMessage 异常提示信息模板
*/
public static <T, R, V> void ensureColumnValueValid(V valueToCheck, SFunction<T, R> columnExtractor, SFunction<LambdaQueryWrapper<T>, T> queryExecutor, String errorMessage) {
if (valueToCheck == null) return;
LambdaQueryWrapper<T> wrapper = new LambdaQueryWrapper<>();
wrapper.select(columnExtractor);
wrapper.eq(columnExtractor, valueToCheck);
wrapper.last("LIMIT 1");
T entity = queryExecutor.apply(wrapper);
R columnValue = columnExtractor.apply(entity);
if (entity == null || columnValue == null)
throw new DataValidationException(String.format(errorMessage, valueToCheck));
}easypoi
三目运算 {{test ? obj:obj2}}
n: 表示 这个cell是数值类型 {{n:}}
le: 代表长度{{le:()}} 在if/else 运用{{le:() > 8 ? obj1 : obj2}}
fd: 格式化时间 {{fd:(obj;yyyy-MM-dd)}}
fn: 格式化数字 {{fn:(obj;###.00)}}
fe: 遍历数据,创建row
!fe: 遍历数据不创建row
$fe: 下移插入,把当前行,下面的行全部下移.size()行,然后插入
#fe: 横向遍历
v_fe: 横向遍历值
!if: 删除当前列 {{!if:(test)}}
单引号表示常量值 ‘’ 比如’1’ 那么输出的就是 1
&NULL& 空格
]] 换行符 多行遍历导出
sum: 统计数据
一般用的多的就是{{n:}}以及{{fe: list t.XXX}},一个的普通的替换,一个是纵向的循环
tips:
1.复杂的表格,比如动态行、动态列可以先把所有的数据导出,每行每列包含基本数据,
2.使用
CellRangeAddress ncra = new CellRangeAddress(2, 2, 1 + ((j) * mergeRow), (j + 1) * mergeRow);
itemWorkbook.getSheetAt(i).addMergedRegion(ncra);
进行合并Spring Event 业务解耦
@Data
@ToString
public class OrderProductEvent extends ApplicationEvent {
/** 该类型事件携带的信息 */
private String orderId;
public OrderProductEvent(Object source, String orderId) {
super(source);
this.orderId = orderId;
}
}
@Slf4j
@Component
public class OrderProductListener implements ApplicationListener<OrderProductEvent> {
/** 使用 onApplicationEvent 方法对消息进行接收处理 */
@SneakyThrows
@Override
public void onApplicationEvent(OrderProductEvent event) {
String orderId = event.getOrderId();
long start = System.currentTimeMillis();
Thread.sleep(2000);
long end = System.currentTimeMillis();
log.info("{}:校验订单商品价格耗时:({})毫秒", orderId, (end - start));
}
}
@Slf4j
@Service
@RequiredArgsConstructor
public class OrderService {
/** 注入ApplicationContext用来发布事件 */
private final ApplicationContext applicationContext;
public String buyOrder(String orderId) {
long start = System.currentTimeMillis();
// 1.查询订单详情
// 2.检验订单价格 (同步处理)
applicationContext.publishEvent(new OrderProductEvent(this, orderId));
// 3.短信通知(异步处理)
long end = System.currentTimeMillis();
log.info("任务全部完成,总耗时:({})毫秒", end - start);
return "购买成功";
}
}
@Data
@AllArgsConstructor
public class MsgEvent {
/** 该类型事件携带的信息 */
public String orderId;
}
@Data
@AllArgsConstructor
public class MsgEvent {
/** 该类型事件携带的信息 */
public String orderId;
}
@Data
@AllArgsConstructor
public class MsgEvent {
/** 该类型事件携带的信息 */
public String orderId;
}render.com
https://dashboard.render.com/jsonobject
JSON.parseArray(JSON.toJSONString(xxx), xxxx.class);ssl
https://csr.chinassl.net/index.html@Cacheable spel
https://docs.spring.io/spring-framework/docs/4.2.x/spring-framework-reference/html/expressions.html
@Cacheable(cacheNames = ENTERPRISE_CACHE_KEY, key = "T(com.emax.common.Md5Util).sign(T(com.alibaba.fastjson.JSON).toJSONString(#root.args[0]))")@Scheduled 关闭定时任务
@Scheduled(cron = "${timjob.readS3FileJob.time:-}"
“-” 表示定时任务不会执行,如果${}对应的参数再配置文件中没有的话,springboot默认会使用-进行填充,即,cron=“-” 表示关闭定时任务。null在不同的语言中标识方法
java null
python None
go nil
javascript undefined null
css none
sql null
to be continued.....java 健壮性 可维护 可扩展 思考
一个没有标准的讨论spel表达式
ExpressionParser parser = new SpelExpressionParser();
在 SpEL 表达式中,我们可以通过 属性名 来获取对应路径的内容,如果涉及到嵌套属性,我们用 '.' 来表示级联关系
1 instanceof T(Integer)
可以通过 T(xxx) 来表示 Class 的实例,静态方法也可以通过这个方式使用
boolean trueValue = parser.parseExpression(
"T(java.math.RoundingMode).CEILING < T(java.math.RoundingMode).FLOOR")
.getValue(Boolean.class);
通过使用 #variableName 来获取执行的变量值
#integers.?[#this > 3]
#root
通过 @xxx 来获取 Spring 容器中的 Bean 实例
name?:'Unknown'
安全指针表达式 ?.
#inventors.![name] 集合子集 意为 获取目标集合中某一字段集合
#{}模板表达式
Elivis运算符 groovy语言引入 表达式1?:表达式2
StandardEvaluationContext sec = new StandardEvaluationContext();
Method parseInt = Integer.class.getDeclaredMethod("parseInt", String.class);
sec.registerFunction("parseInt1", parseInt);
sec.setVariable("parseInt2", parseInt);
{1,2,3} 内联list
SpEL目前支持所有集合类型和字典类型的元素访问,使用“集合[索引]”访问集合元素,使用“map[key]”访问字典元素;
@Value ("#{systemProperties['user.dir']}")
private String userDir;
@Value("#{T(java.util.Arrays).asList('one', 'two', 'three')}")
private List<String> strings;
@Pointcut("@annotation(com.example.MyCustomAnnotation) && #root.target.getClass().getSimpleName().startsWith('MyService')")
public void myPointcut() {
}tree还可以这么弄!!!
public static List<MenuVo> makeTree(List<MenuVo> allDate, Predicate<MenuVo> rootCheck, BiFunction<MenuVo, MenuVo, Boolean> parentCheck, BiConsumer<MenuVo, List<MenuVo>> setSubChildren) {
// 1、获取所有根节点
List<MenuVo> roots = allDate.stream().filter(x->rootCheck.test(x)).collect(Collectors.toList());;
// 2、所有根节点设置子节点
roots.stream().forEach(x->makeChildren(x,allDate,parentCheck,setSubChildren));
return roots;
}
public static MenuVo makeChildren(MenuVo root, List<MenuVo> allDate,BiFunction<MenuVo, MenuVo, Boolean> parentCheck, BiConsumer<MenuVo, List<MenuVo>> setSubChildren) {
//遍历所有数据,获取当前节点的子节点
allDate.stream().filter(x->parentCheck.apply(root,x)).forEach(x->{
makeChildren(x, allDate,parentCheck,setSubChildren);
//将是当前节点的子节点添加到当前节点的subMenus中
setSubChildren.accept(x,allDate);
});
return root;
}arthas
java -jar arthas-boot.jar --repo-mirror aliyun --use-httpognl
https://commons.apache.org/dormant/commons-ognl/language-guide.html
Ognl、SpEL、Groovy、Jexl3长事务
1: 方法拆分
2:
TransactionStatus status = transactionManager.getTransaction(new DefaultTransactionDefinition());
try {
// 长事务的处理逻辑
transactionManager.commit(status);
} catch (Exception e) {
transactionManager.rollback(status);
throw e;
}
事务失效、长事务处理及其优化springboot插件化
META-INF/spring.factories
public static void loadJarFile(File path) throws Exception {
URL url = path.toURI().toURL();
URLClassLoader classLoader = (URLClassLoader) ClassLoader.getSystemClassLoader();
//Method method = URLClassLoader.class.getDeclaredMethod("sendMsg", Map.class);
Method method = URLClassLoader.class.getMethod("sendMsg", Map.class);
method.setAccessible(true);
method.invoke(classLoader, url);
}
List<SmsPlugin> smsServices= SpringFactoriesLoader.loadFactories(SmsPlugin.class, null);Transactional ⼯作原理
@Transactional 是基于 AOP 实现的,AOP ⼜是使⽤动态代理实现的。
如果⽬标对象实现了接⼝,默认 情况下会采⽤ JDK 的动态代理
如果⽬标对象没有实现了接⼝,会使⽤ CGLIB 动态代理。