
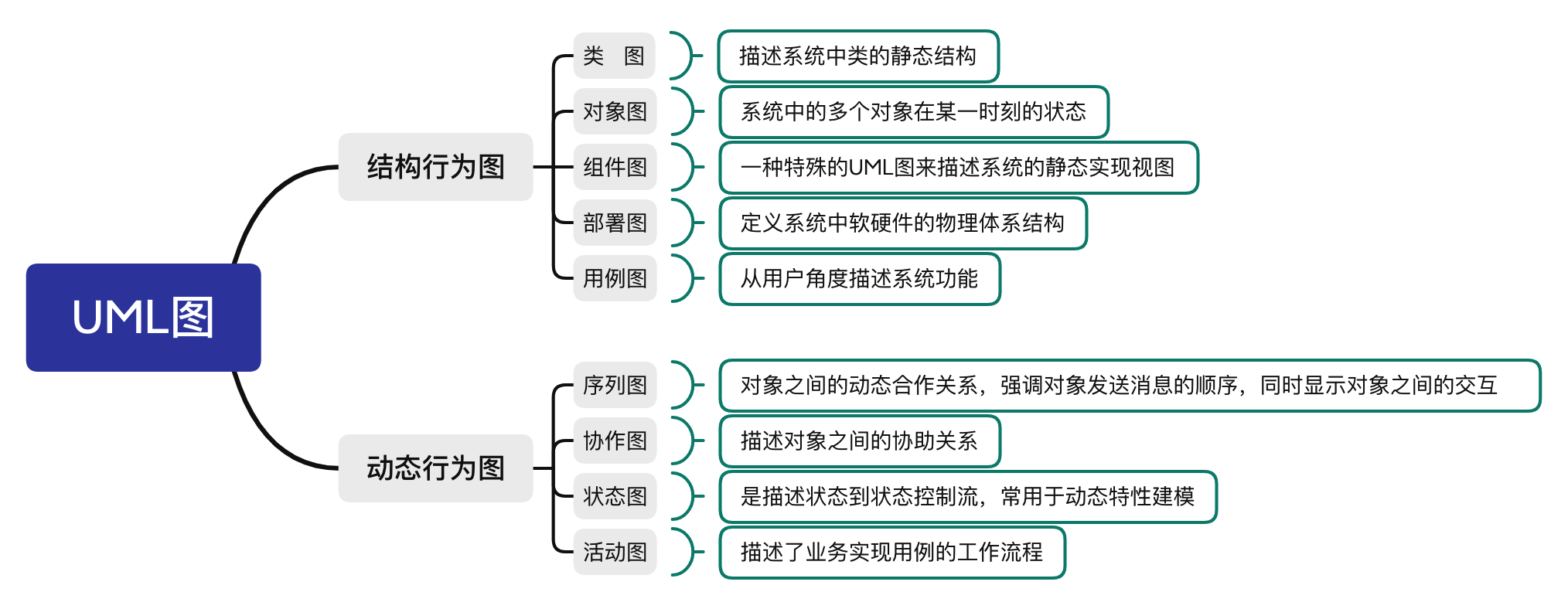
uml
.jpeg)
.png)
语言对比
Java:
领域:Web开发、移动开发、企业应用开发和大数据等领域。
优点:跨平台、面向对象、稳定可靠、开发效率高、安全性好、丰富的第三方库和框架。
缺点:性能一般、代码量大。
Golang:
领域:高并发、分布式系统、网络编程、云计算、服务端开发等领域。
优点:高并发、编译速度快、内存使用低、简洁易学、开发效率高。
缺点:类型系统相对简单、生态系统相对不完善、学习曲线较陡峭。
Python:
领域:机器学习、科学计算、Web开发、数据分析、自动化等领域。
优点:简洁易学、丰富的第三方库和框架、多用途、可读性强、适合快速原型开发。
缺点:性能相对较慢、不适合大规模开发、GIL全局解释器锁的存在会影响多线程编程。ansible
ansible是自动化运维工具的一种,基于Python开发,可以实现批量系统配置,批量程序部署,批量运行命令
ansible是基于模块工作的,它本身没有批量部署的能力,真正工作的是ansible所运行的模块,ansinble只是提供了一个框架。
最大的特点,无客户端(基于SSH和Python)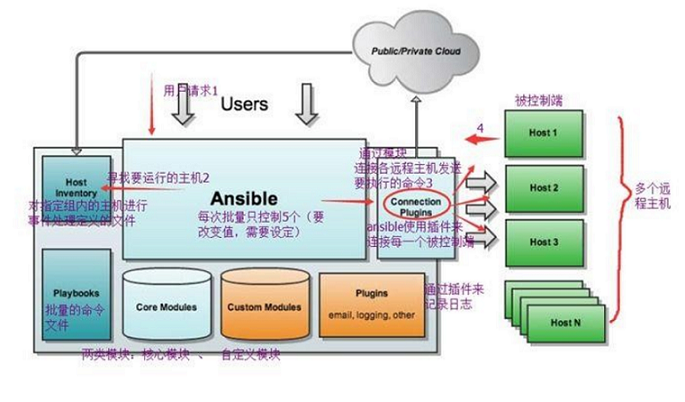
Ansible:Ansible核心程序。
HostInventory:记录由Ansible管理的主机信息,包括端口、密码、ip等。
Playbooks:“剧本”YAML格式文件,多个任务定义在一个文件中,定义主机需要调用哪些模块来完成的功能。
CoreModules:核心模块,主要操作是通过调用核心模块来完成管理任务。
CustomModules:自定义模块,完成核心模块无法完成的功能,支持多种语言。
ConnectionPlugins:连接插件,Ansible和Host通信使用
ansible 任务执行模式
Ansible 系统由控制主机对被管节点的操作方式可分为两类,即adhoc和playbook:
ad-hoc模式(点对点模式)
使用单个模块,支持批量执行单条命令。ad-hoc 命令是一种可以快速输入的命令,而且不需要保存起来的命令。就相当于bash中的一句话shell。
playbook模式(剧本模式)
是Ansible主要管理方式,也是Ansible功能强大的关键所在。playbook通过多个task集合完成一类功能,如Web服务的安装部署、数据库服务器的批量备份等。可以简单地把playbook理解为通过组合多条ad-hoc操作的配置文件。
ansible配置文件查找顺序
ansible与我们其他的服务在这一点上有很大不同,这里的配置文件查找是从多个地方找的,顺序如下:
检查环境变量ANSIBLE_CONFIG指向的路径文件(export ANSIBLE_CONFIG=/etc/ansible.cfg);
~/.ansible.cfg,检查当前目录下的ansible.cfg配置文件;
/etc/ansible.cfg检查etc目录的配置文件。
ansible -m ping dev
ansible all --list-host
ping模块
ansible all -m ping -b --become-user root
command模块
ansible -m command -a 'df -h' dev
shell模块
ansible -m shell -a 'ps -ef' dev
copy模块
file模块
fetch模块
cron模块
yum模块
service模块
user模块
group模块
script模块
setup模块
find 模块
synchronize 模块
playbook 剧本
hosts:运行执行任务(task)的目标主机
remote_user:在远程主机上执行任务的用户
tasks:任务,由模板定义的操作列表
handlers:任务,与tasks不同的是只有在接受到通知(notify)时才会被触发
templates:模板,使用模板语言的文本文件,使用jinja2语法。
variables:变量,变量替换{{ variable_name }}
roles:角色
ansible-playbook playbook.yml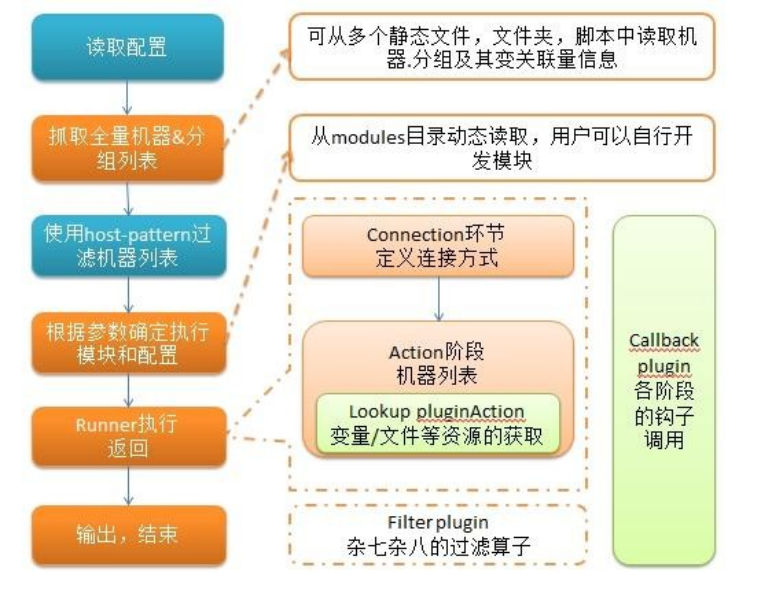
杂项
ip schme
Linux 三剑客
Linux 三剑客是指的 grep、sed、awk 三个命令,grep 主打查找功能,sed 主要是编辑,awk 主要是分割处理。
grep
grep 语法结构
grep [options] [pattern] file
命令 参数 匹配模式 文件数据
-i : 忽略大小写;
-o : 仅显示匹配到目标字符串;
-v : 显示不能被匹配到的字符串(反转);
-E : 支持使用扩展的正则表达式字符串;
-q : 静默模式,不输出任何信息
-n 显示匹配行与行号
-w 只输出过滤的单词
基本常用正则表达式汇总
^ 用于模式最左侧,如 “^yu” 即匹配以 yu 开头的单词
$ 用于模式最右侧,如 “yu$” 即匹配以yu结尾的单词
^$ 组合符,表示空行
. 匹配任意一个且只有一个字符,不能匹配空行
| 转义字符
重匹配前一个字符连续出现 0 次或 1 次以上
._ 匹配任意字符
^._ 组合符,匹配任意多个字符开头的内容
.\*$ 组合符,匹配任意多个字符结尾的内容
[abc] 匹配 [] 内集合中的任意一个字符,a 或 b 或 c,也可以写成 [ac]
[^abc] 匹配除了 ^后面的任意一个字符,a 或 b 或 c,[]内 ^ 表示取反操作
扩展正则表达式
* #匹配零个或多个先前字符 如:'*grep'匹配所有一个或多个空格后紧跟grep的行。
.* #一起用代表任意字符。
[] #匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
[^] #匹配一个不在指定范围内的字符
\(..\) #标记匹配字符,如'\(love\)',love被标记为1。
\< #锚定单词的开始,如:'\<grep'匹配包含以grep开头的单词的行。
\> #锚定单词的结束,如'grep\>'匹配包含以grep结尾的单词的行。
x\{m\} #重复字符x,m次,如:'0\{5\}'匹配包含5个o的行。
x\{m,\} #重复字符x,至少m次,如:'o\{5,\}'匹配至少有5个o的行。
x\{m,n\}#重复字符x,至少m次,不多于n次,如:'o\{5,10\}'匹配5--10个o的行。
\w #匹配文字和数字字符,也就是[A-Za-z0-9],
\W #\w的反置形式,匹配一个或多个非单词字符,如点号句号等。
\b #单词锁定符,如: '\bgrep\b'只匹配grep。
a 或 --text 不要忽略二进制的数据。
-A<显示行数> 或 --after-context=<显示行数> 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-b 或 --byte-offset 在显示符合样式的那一行之前,标示出该行第一个字符的编号。
-B<显示行数> 或 --before-context=<显示行数> 除了显示符合样式的那一行之外,并显示该行之前的内容。
-c 或 --count 计算符合样式的列数。
-C<显示行数> 或 --context=<显示行数>或-<显示行数> 除了显示符合样式的那一行之外,并显示该行之前后的内容
-d <动作> 或 --directories=<动作> 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep指令将回报信息并停止动作
-e<范本样式> 或 --regexp=<范本样式> 指定字符串做为查找文件内容的样式。
-E 或 --extended-regexp 将样式为延伸的正则表达式来使用。
-f<规则文件> 或 --file=<规则文件> 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。
-F 或 --fixed-regexp 将样式视为固定字符串的列表。
-G 或 --basic-regexp 将样式视为普通的表示法来使用。
-h 或 --no-filename 在显示符合样式的那一行之前,不标示该行所属的文件名称。
-H 或 --with-filename 在显示符合样式的那一行之前,表示该行所属的文件名称。
-i 或 --ignore-case 忽略字符大小写的差别。
-l 或 --file-with-matches 列出文件内容符合指定的样式的文件名称。
-L 或 --files-without-match 列出文件内容不符合指定的样式的文件名称。
-n 或 --line-number 在显示符合样式的那一行之前,标示出该行的列数编号。
-o 或 --only-matching 只显示匹配PATTERN 部分。
-q 或 --quiet或–silent 不显示任何信息。
-r 或 --recursive 此参数的效果和指定"-d recurse"参数相同
-s 或 --no-messages 不显示错误信息
-v 或 --invert-match 显示不包含匹配文本的所有行
-V 或 --version 显示版本信息。
-w 或 --word-regexp 只显示全字符合的列
-x --line-regexp 只显示全列符合的列
-y 此参数的效果和指定"-i"参数相同
sed 编辑
-e 脚本命令 该选项会将其后跟的脚本命令添加到已有的命令中。
-f 脚本命令文件 该选项会将其后文件中的脚本命令添加到已有的命令中。
-n 默认情况下,sed 会在所有的脚本指定执行完毕后,会自动输出处理后的内容,而该选项会屏蔽启动输出,需使用 print 命令来完成输出。
-i 此选项会直接修改源文件,要慎用。
sed s 替换脚本
[address]s/pattern/replacement/flags
address 表示指定要操作的具体行,pattern 指的是需要替换的内容,replacement 指的是要替换的新内容。
n 1~512 之间的数字,表示指定要替换的字符串出现第几次时才进行替换,例如,一行中有 3 个 A,但用户只想替换第二个 A,这是就用到这个标记;
g 对数据中所有匹配到的内容进行替换,如果没有 g,则只会在第一次匹配成功时做替换操作。例如,一行数据中有 3 个 A,则只会替换第一个 A;
p 会打印与替换命令中指定的模式匹配的行。此标记通常与 -n 选项一起使用。
w file 将缓冲区中的内容写到指定的 file 文件中;
& 用正则表达式匹配的内容进行替换;
\n 匹配第 n 个子串,该子串之前在 pattern 中用 \(\) 指定。
\ 转义(转义替换部分包含:&、\ 等)。
sed d 替换
[address]d
sed a 和 i 脚本命令
a 命令表示在指定行的后面附加一行,i 命令表示在指定行的前面插入一行
[address]a(或 i)\新文本内容
sed c 替换脚本命令
[address]c\用于替换的新文本
sed p 打印脚本命令
[address]p
sed w 脚本命令
[address]w filename
awk 处理文本、格式化文本
awk [参数] [处理内容] [操作对象]
awk 中的变量
$0: 保存当前行的内容
NR: 记录号(行号),每处理完一条记录,NR 值加 1
NF: 保存记录的字段数(总共保存的列数),$1,$2...$100
FS: 输入字段分隔符,默认空格
OFS:输出字段分隔符
FNR 当前行在源文件中的行数
表达式
BEGIN BEGIN 和 END 是两种特殊的模式,没有针对输入进行测试。所有 BEGIN 模式的动作部分都被合并,就好像所有语句都写在一个 BEGIN 块中一样。它们在读取任何输入之前执行。
END 所有的结束块都被合并,当所有的输入都被耗尽时(或者当执行 exit 语句时)执行。开始和结束模式不能与模式表达式中的其他模式组合。开始和结束模式不能缺少动作部分。
BEGINFILE BEGINFILE 和 ENDFILE 是附加的特殊模式,其主体在读取每个命令行输入文件的第一条记录之前和读取每个文件的最后一条记录之后执行。
ENDFILE
/regular expression/ 对于/regular expression/patterns,将对与正则表达式匹配的每个输入记录执行关联语句。正则表达式与 egrep(1)中的表达式相同,总结如下。
relational expression 关系表达式可以使用下面关于操作一节中定义的任何运算符。它们通常测试某些字段是否与某些正则表达式匹配。
pattern && pattern 逻辑 AND,与 C 中的运算符相同。它们进行短路计算,也与 C 中的运算符相同,用于组合更原始的模式表达式。
pattern||pattern 逻辑 OR,与 C 中的运算符相同。它们进行短路计算,也与 C 中的运算符相同,用于组合更原始的模式表达式。
pattern ? pattern : pattern 这个?:运算符类似于 C 中的同一运算符。如果第一个模式为真,则用于测试的模式为第二个模式,否则为第三个模式。第二和第三种模式中只有一种是可以执行的。
(pattern)
! pattern 逻辑 NOT,与 C 中的运算符相同。它们进行短路计算,也与 C 中的运算符相同,用于组合更原始的模式表达式。
pattern1, pattern2 表达式的 pattern1,pattern2 形式称为范围模式。它匹配所有输入记录,从匹配 pattern1 的记录开始,一直到匹配 pattern2 的记录为止(包括 pattern2)。它不与任何其他类型的模式表达式相结合。
运算符
控制语句
if (condition) statement [ else statement ]
while (condition) statement
do statement while (condition)
for (expr1; expr2; expr3) statement
for (var in array) statement
break
continue
delete array[index]
delete array
exit [ expression ]
{ statements }
switch (expression) {
case value|regex : statement
...
[ default: statement ]
}
I/O语句
I/O Statements
The input/output statements are as follows:
close(file [, how]) 关闭文件、管道或协同处理。只有在将双向管道的一端封闭到co流程时,才应使用可选方式。它必须是字符串值,可以是“to”或“from”。
getline 从下一个输入记录中设置$0;设置NF、NR、FNR。
getline <file 文件集$0,来自文件的下一条记录;设置NF。
getline var 从下一个输入记录中设置var;设置NR,FNR。
getline var <file 文件的下一条记录中的文件集var。
command | getline [var] 运行命令,将输出管道化为$0或var,如上所述。
command |& getline [var] 以协同进程的形式运行命令,将输出管道化为$0或var,如上所述。协同过程是一个笨拙的扩展。(命令也可以是套接字。请参阅“特殊文件名”小节)
next 下一步停止处理当前输入记录。读取下一条输入记录,处理从AWK程序中的第一个模式开始。如果到达输入数据的末尾,则执行结束块(如果有)。
nextfile 停止处理当前输入文件。读取的下一个输入记录来自下一个输入文件。FILENAME和argid更新,FNR重置为1,处理从AWK程序中的第一个模式。如果到达输入数据的末尾,则执行结束块(如果有)。
print 打印当前记录。输出记录以ORS变量的值终止。
print expr-list 打印表达式列表打印表达式。每个表达式由OFS变量的值分隔。输出记录以ORS变量的值终止。
printf fmt, expr-list Format and print. 打印fmt、expr列表格式和打印。参见下面的printf语句。
printf fmt, expr-list >file 格式化并打印文件。
system(cmd-line) 系统(cmd行)执行命令cmd行,并返回退出状态。(这在非POSIX系统上可能不可用。)
fflush([file]) 刷新与打开的输出文件或管道文件关联的所有缓冲区。如果文件丢失或为空字符串,则刷新所有打开的输出文件和管道。print和printf允许额外的输出重定向。
print ... >> file 将输出附加到文件。
print ... | command 在管道上写字。
print ... |& command 将数据发送到协同进程或套接字。getline命令成功时返回1,文件结束时返回0,错误时返回-1。出现错误时,ERRNO包含一个描述问题的字符串。
注意:如果无法打开双向套接字,则会将非致命错误返回给调用函数。如果在一个循环中使用管道、协进程或套接字来获取行,或从print或printf,则必须使用close()创建命令或套接字的新实例。当管道、插座或co进程返回EOF时,AWK不会自动关闭它们。Linux find 在目录中查找文件
-name 查找 /etc 目录下以 conf 结尾的文件,文件名区分大小写,例如:find /etc -name '\*.conf'
-iname 查找当前目录下所有文件名为 aa 的文件,文件名不区分大小写,例如:find . -name aa
-user 查找文件所属用户为 zhangsan 的所有文件,例如:find . -user zhangsan
-group 查找文件所属组为 dev 的所有文件,例如:find . -group dev
-type 根据类型查找:如下
f 文件 find . -type f
d 目录 find . -type d
c 字符设备文件 find . -type c
b 块设备文件 find . -type b
l 链接文件 find . -type l
p 管道文件 find . -type p
-size 根据文件大小查询
-n 小于 大小为 n 的文件
+n 大于 大小为 n 的文件
举例 1:查找 /ect 目录下,小于 10000 字节的文件。 find /etc -size -10000c
举例 2:查找 /etc 目录下,大于 1M 的文件。find /etc -size +1M
-mtime
-n n 天以内修改的文件。
+n n 天以外修改的文件。
n 正好 n 天 修改的文件
举例 1: 查询 /etc 目录下,5 天以内修改 且以 conf 结尾的文件。 find /etc -mtime -5 -name '\*.conf'
举例 2: 查询 /etc 目录下,10 天之前修改,且属于 yangyang 的文件。 find /etc -mtime +10 -user yangyang
-mmin
-n n 分钟以内修改过的文件
+n n 分钟之前修改过的文件
举例 1: 查询 /etc 目录下 30 分钟 之前修改过的文件。 find /etc -mmin +30
举例 1: 查询 /etc 目录下 30 分钟 之内修改过的目录。 find /etc -mmin -30 -type d
-mindepth n 从第 n 级目录开始搜索
举例:从 /etc 的第三级子目录开始搜索。 find /etc -mindepth 3
-maxdepth n 表示至多搜索到第 n-1 级子目录。
举例 1: 在 /etc 中搜索符合条件的文件,但最多搜索到 2 级 子目录。 find /etc -maxdepth 3 -name '\*.conf'
举例 2: find /etc -type f -name '\*.conf' -size +10k -maxdepthc 2
-print 打印输出。 默认的选项,即打印出找到的结果。
-exec 对搜索到的文件执行特定的操作,固定的格式为:-exec 'commond' {} \; 注意:{} 表示查询的结果。
举例 1: 搜索 /etc 目录下的文件(非目录),文件以 conf 结尾,且大于 10k,然后将其删除。
find /etc -type f -name '\*.conf' -size +10k -exec rm -f {} \;
举例 2: 将 /data/log/ 目录下以 .log 结尾的文件,且更改时间在 7 天以上的删除。
find /data/log -name '\*.log' -mtime +7 -exec rm -f \;
举例 3: 搜索条件同 例 1 一样,但是不删除,只是将其复制到 /root/conf 目录下
find /etc -type f -name '\*.conf' -size +10k -exec cp {} /root/conf/ \;
-ok 和 -exec 的功能一样,只是每次操作都会给用户提示。
-a 与 (默认情况查询条件之间都是 与 的关系)
-o 或
-not | ! 非expect 自动化交互式操作
spawn:交互程序开始后面跟命令或者指定程序(在壳内启动这个进程)
expect:获取匹配信息匹配成功则执行expect后面的程序动作(检测由壳内进程发出的特定交互指令反馈字符串后向下执行)
send:用于向进程发送字符串(从壳外向壳内进程发送一条字符串,换行符为确认结束)
interact:允许用户交互
exp_continue:在expect中多次匹配就需要用到
send_user:用来打印输出 相当于shell中的echo
exit:退出expect脚本
eof:expect执行结束 退出
set:定义变量
puts:输出变量
set timeout:设置超时时间
-d
启用一些诊断输出,主要报告 expect 和 interaction 等命令的内部活动。
-D
启用交互式调试器。后面应该是一个整数值。如果值非零或按下^C(或击中断点,或脚本中出现其他适当的调试器命令),调试器将在下一个 Tcl(Tool Command Language) 过程之前接管控制。
-i
交互式输入 expect 命令,而不是从文件中读取。通过 exit 命令或 EOF 终止。
-n
不使用 ~/.expect.rc 脚本。
-N
不使用 $exp_library/expect.rc 脚本。
-c <cmds>
指定要执行的 expect 命令。命令应该加引号,以防止被 Shell 分解。此选项可使用多次或用一个 -c 选项指定多个命令,命令之间用分号分隔。命令按照它们出现的顺序执行。
-f
从文件读取命令,仅用于使用#!时。如果文件名为"-",则从stdin读取(使用"./-"从文件名为-的文件读取)。
-b
默认情况下,命令文件被读入内存并完整地执行。有时需要一次读取一行。例如,stdin 是这样读取的。为了强制任意文件以这种方式处理,请使用 -b 选项。
-v
显示 expect 版本信息。测试
冒烟测试、回归测试、渗透测试、黑盒测试、白盒测试、灰盒测试
1、测试方案:写明将要如何进行测试的文档,包括测试计划、测试环境、测试数据、测试工具、测试方法、风险依赖等方面。
2、测试方案参考目录(可根据项目或产品需要适当删减)
(1)功能测试、模块 1、模块 2、模块 3、接口测试、测试内容
(2)包含系统的哪些模块哪些方面(功能、性能、数据)、测试范围、测试环境 、测试工具 、测试数据、测试方法 、测试人力资源安排、测试进度安排、测试输出 、风险分析 、硬件环境、软件环境、借助到的一些测试浏览器兼容性工具、自动化测试工具、性能测试工具
(3)黑盒测试、白盒测试、冒烟测试、验收测试、包含哪些文档、报告等、一般有:测试计划、测试方案、系统评测报告、缺陷报告等、系统上线后可能会出现的问题,一些现在尚未解决的 bug,各种使用环境可能出现的问题等;
(4)编写目的、读者对象、项目背景、测试目标、参考资料、概述 、测试计划 、集成测试用例 、系统测试用例 、性能测试
一、立项后测试需要拿到的文档
1、需求说明书
2、原型图(及 UI 图)
3、接口文档
4、数据库字典(表的数量、缓存机制)
二、需求评审
三、用例编写(同时根据开发计划编写测试计划)
用例功能类型
所在就职部门将用例分成 7 类:
1、主流程:该模块实现的主要功能流程。
2、备选流:不一定完成执行一个功能,而是终止了流程。
3、异常流:由于某些异常原因,使流程的功能无法实现。
4、业务规则:必填项,强制的要求。
5、正常类:返回功能、必填项输入范围、页面按钮的切换等。
6、异常类:网络异常、返回异常等。
7、界面检查:针对每个页面的样式及内容检查。
测试用例的编写方法
1、等价类划分
2、边界值分析法
3、错误推断法
4、因果分析法
5、场景法
五、测试执行
**showcase 测试:**测试到开发的电脑上进行,主要执行一下关键测试用例、流程用例,由开发操作,测试人员一起查看。showcase 不通过,则打回,邮件发出。
**冒烟测试:**showcase 测试通过后,提交到测试,由测试人员开始大量跑关键测试用例。若针对某个模块跑用例时,出现较多问题,则也可重新打回给开发。冒烟测试报告邮件如下字段:测试模块 是否通过 不通过原因 测试详情 备注
邮件描述大致如下:以下是截止到某个日期,已提交的功能冒烟测试结果,都不通过,详情如下:
ps:冒烟测试不通过的原因基本上都是。。。。。,麻烦大家相互配合,早点修复提测,谢谢~
**功能测试:**功能测试在手工测试中是主要的阶段,这个阶段主要是全量跑测试用例,提交 bug 到缺陷管理工具。
1、表单测试:
a、表单数据的字段、完整性及表单输入框的长度限制问题
b、一些常理性逻辑验证,比如:出生日期和职业,工作年限是否恰当,所在地省份城市区域间的匹配等,如果设定使用默认值,也需要测试。
2、导航测试:
导航测试,就是在不同的页面跳转之间,或者按钮、对话框、列表以及窗口等,通过考虑这些因素去判断一个应用是否易于导航:是否直观?系统的主要模块是否可以通过主页访问或者到达?站点是否需要站内地图或者搜索引擎等其他帮助?web 系统导航的另外一个重点就是页面结构、导航、菜单、风格等是否一致,确保用户可以凭借直觉或者简单的判断就可以找到自己想要的内容。(参考博客http://www.cnblogs.com/imyalost/p/5622867.html)
3、UI 测试:
也可以理解为 UI 测试,其中包括图片、动画、边框、颜色、字体、背景、按钮等等。
注: 其中要考虑的几个重点,我做了一个大概的总结:
a、图片要有明确的用途,代表;图片尺寸尽量小,一般采用 JPG 或者 GIF 压缩(即规格大小的限制)
b、页面整体风格是否和系统的用途一致
c、背景颜色,字体,搭配是否合理
4、内容测试:
这个主要用来检测 web 系统提供信息的准确性、相关性。
比如:商品的价格,文字描述;信息的准确性,是否有拼写错误;(这点比较容易忽略,需要多注意)信息的相关性,比如很多网站的“相关文章列表,视频列表等”
5、整体界面测试
a、 这个也就是我们常说的用户体验。用户浏览时是否感觉舒适,整体风格等等
b、建议一般做一个类似问卷调查的形式,来判定用户的反馈信息,最好有最终用户的参与,可参考类似的笔记哦啊普遍的系统风格是怎样的,结合实际来考虑本测试系统的风格
6、链接测试(平时在测试过程中并不关注,而是在权限分配的安全测试中比较注重,主要是不同权限的人分享的链接是否能正确过滤,保证安全)
7、输入框测试(粘贴博客http://www.cnblogs.com/imyalost/p/5622867.html)
在 web 测试中,我们经常遇到这种输入框的测试,输入框测试看似简单,实际上包含了很多的测试基本的方法,思考逻辑,下面就是我总结出来的一些注意点:
1)验证输入输出信息的一致性
2)输入框前面的文字提示是否正确
3)对特殊字符的处理、识别:单双引号,括号,逗号、分号等等,以及大小写状态,半角全角状态下的情况
4)输入框的大小、长度、边框等
5)不同字符的输入,以及字符组合情况的处理(数字+字母+字符等)
6)对空格、tab 换行键的处理机制
7)密码输入框字符星号或者其他星号的转行,加密
8)输入框输入字符长度是否有限制
9)字符本身显示的颜色,规格等
10)有些输入框需要加以限制,如输错,是否有提示?提示是否简单合理?
11)输入状态,某种情况下输入框出于不可编辑,当再次处于编辑状态,输入框的输入状态是否有变化?
12)输入类型:是否允许复制黏贴剪切等输入操作
13)关键字是否支持通配符,以及关键字的搜索能力,敏感字等情况
14)输入框输入空格的情况
15)比如登陆注册,各项输入条件的判定:是否输入,输入是否正确等
8、用户权限测试(粘贴博客http://www.cnblogs.com/imyalost/p/5622867.html)
用户权限,顾名思义,就是该账号拥有哪些执行操作的权利
1)给某账号赋予权限后,登陆该账号,查看是否拥有已赋予的权限,以及权限设置是否正确(权限是否超过或者不足)
2)删除或修改已经登陆并且正在执行操作的账号权限,程序能否正确处理,验证
3)重新注册系统变更登陆身份后再登陆,程序能否正确执行,之前所拥有的权限能否继续使用
4)在用工作分配或者角色管理情况下,删除包含用户的工作组或者角色,程序能否正确处理
5)不同权限账号登陆同一个系统,权限范围是否正确
6)能否给信息为空、长用户名的账号添加权限
7)是否允许删除系统管理员或者修改管理员权限?删除或者修改后的实际情况
8)已登录的用户能否修改或者删除自己或者他人的权限,信息
9)添加用户(有编号或者标识),不同用户名标识的组合情况下,权限能否处理正确
10)修改用户权限或者信息后,对其他模块是否有影响
11)如果修改用户信息为和已存在的其他用户信息相同,能否修改成功?是否有对应提示?
12)修改某些设置,是否会对与该账号权限相同或者高于/低于该账号的其他账号的权限造成影响
13)同一用户是否可以同时属于其他组,各个组的权限能否交叉?
回归测试:
回归测试书要是根据在测试执行过程中记录的 bug 及执行失败的用例来进行的,根据记录的 bug 进行验证是否已经修改更新好,必要时,根据 bug 量的多少来评估是否需要重新跑一下系统的流程。
兼容性测试:(参考博客http://www.cnblogs.com/imyalost/p/5622867.html)
a、平台兼容
在有很多的操作系统,比如 Windows、Unix、Linux、macintosh 等;用户使用哪个系统取决于用户,因此,系统兼容测试就很有必要了。
b、浏览器兼容
浏览器是 web 客户端最核心的组件,不同的浏览器,对 Java,JavaScript,css 或者 HTML 的规格都有不同的支持;
另外,采用的框架和结构风格在不同浏览器中也存在不同的显示甚至不显示,不同的浏览器对安全性的设置也是不同的。
测试浏览器兼容,有个方法就是创建一个兼容性矩阵,来测试不同厂商不同版本的浏览器兼容。
比如测试 IE 浏览器,可以通过一个叫做 IEtester 的工具来测试兼容,或者可以通过 F12 控制台来切换浏览器版本来测试兼容以前一些前端元素的显示等
鉴于国内市场浏览器很多,比如 360、搜狗,搜狐、QQ 浏览器等,这些本土的浏览器基本都采用的 IE 浏览器内核的双核配置
安全测试:
安全测试的主要区域有以下几点:
a、现在很多 web 应用系统都采用先注册后登录的方式,因此,测试用户名和密码的有效无效性,注意大小写敏感,次数限制,是否可以不登录而浏览某些页面等
b、是否有超时限制,链接分享,cookie 劫持
c、测试用户操作时相关信息是否写入了日志文件、是否可追踪等
d、如果使用了安全套字,需要测试加密是否正确,加密前后的信息完整性,正确性
e、没有经过授权,是否可以在服务器端或者前端放置和编辑脚本的问题
f、输入框的 SQL 注入验证
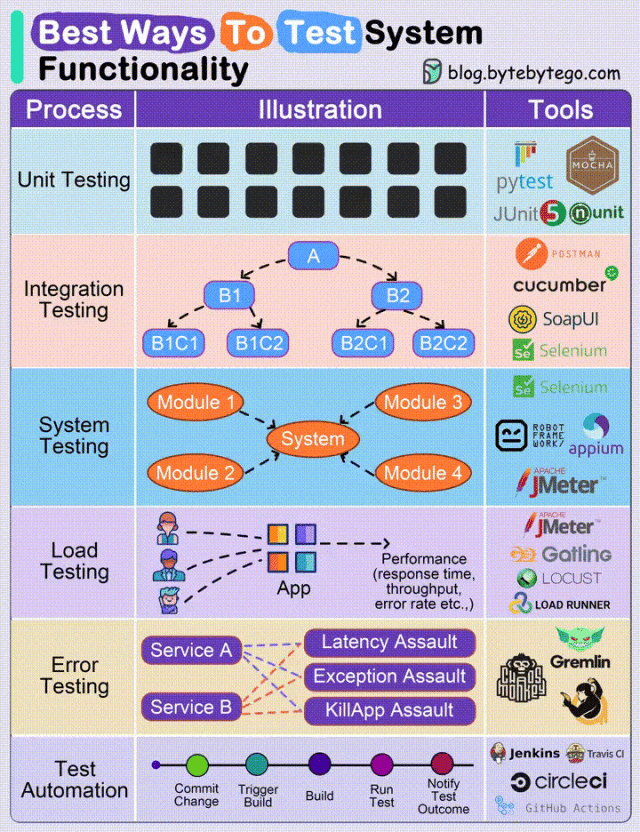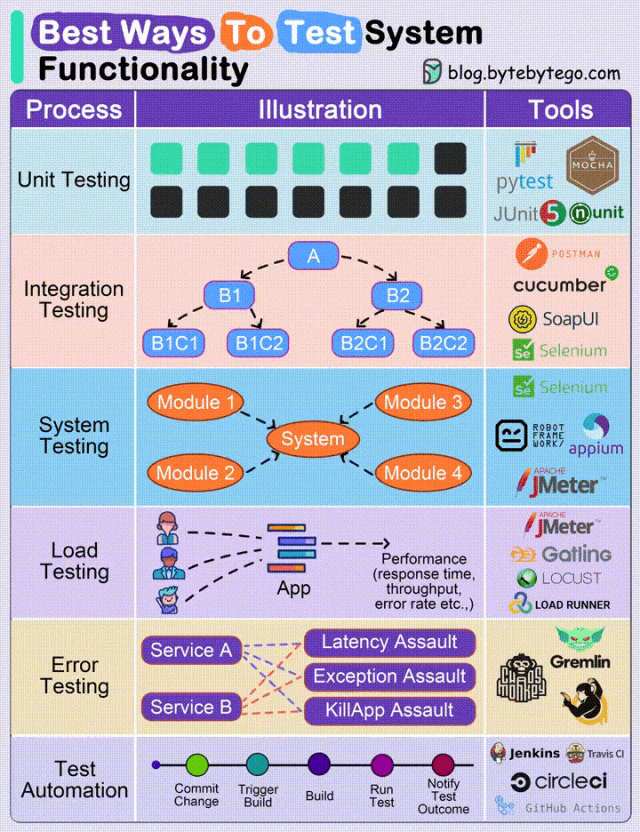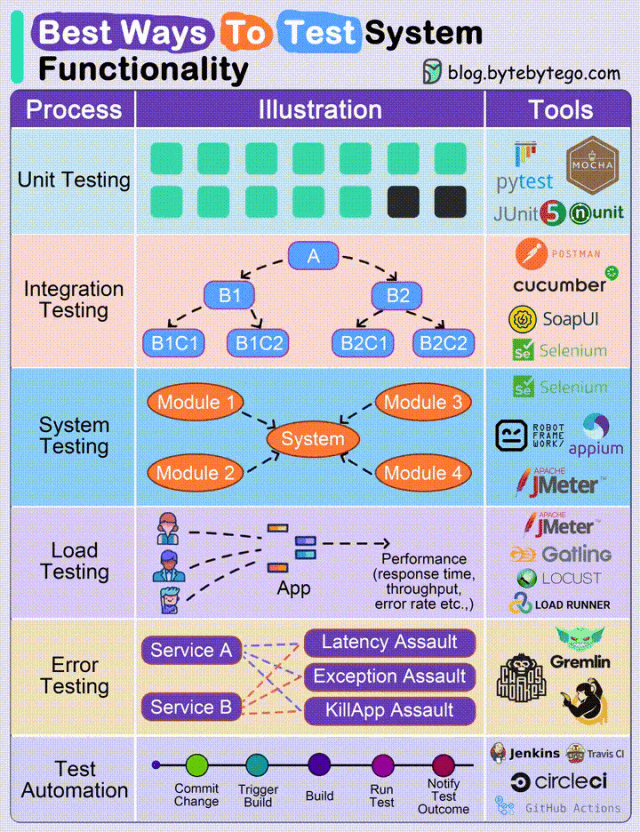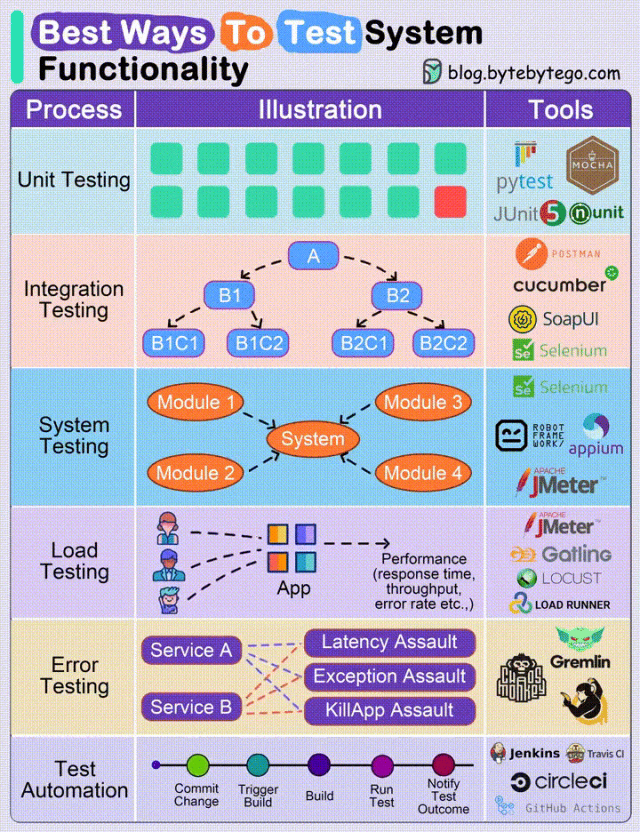
临时邮箱
高可用
熔断 防止故障扩散 快速失败
- sentinel
限流 控制系统请求 系统突发流量
- 固定窗口计数限流算法
滑动窗口计数限流算法
令牌桶算法
降级 保持系统可用 边缘服务
开关硬编码
aop
策略/工厂模式
vscode
serialVersionUID
import java.io.Serializable
.settings
org.eclipse.jdt.core.prefs->org.eclipse.jdt.core.compiler.problem.missingSerialVersion=warningssh
T参数来指定不分配伪终端,提高连接传输效率,通过i来返回交互式shell。
如果用SSH连接目标机时,默认的ssh直接连接,目标机在last或者who都可以看到记录,这里尝试如果带个终端的话,则不会有记录。
ssh -T test@192.168.10.10 /bin/bash -i
ssh -LR 端口转发 -L监听 -R转发
host1可以和host3相互通信,host3可以和host2相互通信,但host1和host2之间不能直接通信 现在需要实现host1和host2之间的通信(前提是要知道host3的用户账号密码) 在host1上执行 ssh -fNg -L 6666:host2:80 host3 ssh -fNg -L 8080:47.94.23.208:19002 ubuntu@172.21.130.255 ssh -fNg -L <本地端口>:<目标主机>:<目标端口> <用户名>@<远程主机> -f 后台转发 -g 网关作用,让其它主机也能访问端口 -N 不执行ssh远程指令 本地转发 -L 远程转发 -R 动态转发 -D
netstat -ano | findstr 8080
taskkill /pid 6148 /f
ssh -R <远程端口>:<目标主机>:<目标端口> <用户名>@<远程主机> ssh -fNgv -R 8001:127.0.0.1:8001 root@remote-ip
ssh本地转发 远程转发 动态转发
cat /dev/null > ~/.bash_history
sudo sed -i "s@#ClientAliveInterval 0@ClientAliveInterval 60@g" /etc/ssh/sshd_config
sudo sed -i "s@#ClientAliveCountMax 3@ClientAliveCountMax 3@g" /etc/ssh/sshd_config
sudo sed -i "s@#TCPKeepAlive yes@TCPKeepAlive yes@g" /etc/ssh/sshd_config
umami
网站流量统计
https://developer.aliyun.com/mirror/
nginx keepalived
mac 地址更改
Technitium MAC Address Changer
markdown
mermaid
flowchat
st=>start: 开始
e=>end: 结束
op=>operation: 我的操作
cond=>condition: 确认?
st->op->cond
cond(yes)->e
cond(no)->opmermaid
graph LR
A[长方形] -- 链接 --> B((圆))
A --> C(圆角长方形)
B --> D{菱形}
C --> D